
🏭 你是不是也遇到过这种情况?
车间里的 PLC 跑得好好的,数据全在里头——但就是没法方便地"拿出来"看。工程师盯着触摸屏,想把实时数据搬到电脑上做分析,翻遍网络,要么是昂贵的 SCADA 软件,要么是晦涩的工业协议文档。折腾半天,脑壳疼。
我在一个离散制造的项目里就踩过这个坑。当时需要把西门子 S7-1200 的温度和压力数据实时展示在操作站的 Windows 电脑上,预算有限,时间紧。最后用 Python + Tkinter + snap7 库,三天搞定了一个能用的监控小工具——不依赖任何商业授权,代码不超过 300 行。
这篇文章就把这套思路完整拆给你看。读完之后,你能拿到:一个可直接运行的 Tkinter GUI 框架、一套PLC 通信的核心代码模板,以及几个我亲自踩过的坑的预警。不废话,直接开干。
🔍 先把问题说透:为什么 PLC 数据"难读"?
很多人第一反应是——PLC 不就是个设备,Python 连上去读不就完了?没那么简单。
PLC 通信有几个坎儿绕不过去:
协议层面:工业设备用的不是 HTTP,是 Modbus、S7、EtherNet/IP 这类工业协议。每种协议的寻址方式、数据类型、字节序都不一样。你以为读到的是个整数,实际上可能是个大端序的 BCD 码。
实时性要求:生产现场的数据刷新周期通常在 100ms ~ 1s 之间。如果你在 GUI 主线程里同步轮询 PLC,界面会卡死——这是新手最常见的问题,没有之一。
连接稳定性:网络抖动、PLC 重启、IP 冲突……这些情况在车间里比你想象的频繁得多。没有重连机制的程序,用不了三天就会被运维骂。
所以,这个问题的核心不只是"怎么读数据",而是如何在 GUI 线程和通信线程之间做好隔离,同时保证程序足够健壮。
🧱 技术选型:为什么是这套组合?
- Tkinter:Python 内置,无需额外安装,Windows 下开箱即用,够用就行,别过度设计
- python-snap7:开源的西门子 S7 协议库,封装成熟,pip 直接装
- threading + queue:Python 标准库,用来做线程间通信,零依赖
如果你用的是 Modbus 设备(比如台达、汇川),把 snap7 换成
pymodbus即可,架构完全一样。
🚀 方案一:最简版本——先跑起来再说
先别急着做完美的架构。第一步,把数据读出来显示在窗口上,验证通路。
环境准备
bashpip install python-snap7
snap7 还需要一个本地的动态库文件。去 python-snap7 官网 下载对应 Windows 版本的 snap7.dll,放到你的项目根目录或者 C:\Windows\System32 下。
代码:单线程轮询(仅用于验证,生产环境慎用)
pythonimport tkinter as tk
import snap7
import time
# ---- PLC 连接参数,按实际情况修改 ----
PLC_IP = "192.168.1.100"
RACK = 0
SLOT = 1
def read_plc_data(client):
"""
读取 DB1.DBD0(双字,4字节浮点数),对应一个温度值
DB编号、偏移量根据你的实际程序调整
"""
try:
data = client.db_read(1, 0, 4) # DB1, 偏移0, 读4字节
value = snap7.util.get_real(data, 0) # 解析为 REAL 类型(即 float)
return round(value, 2)
except Exception as e:
return f"读取失败: {e}"
def main():
client = snap7.client.Client()
client.connect(PLC_IP, RACK, SLOT)
root = tk.Tk()
root.title("PLC 数据监控 - 简版")
root.geometry("300x150")
label_title = tk.Label(root, text="DB1.DBD0 温度值", font=("微软雅黑", 12))
label_title.pack(pady=10)
label_value = tk.Label(root, text="--", font=("微软雅黑", 28, "bold"), fg="#e74c3c")
label_value.pack()
label_unit = tk.Label(root, text="°C", font=("微软雅黑", 14))
label_unit.pack()
def update():
val = read_plc_data(client)
label_value.config(text=str(val))
root.after(1000, update) # 每 1000ms 刷新一次
update()
root.mainloop()
client.disconnect()
if __name__ == "__main__":
main()
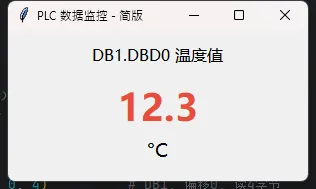
跑起来之后,你会看到一个窗口,每秒刷新一次温度值。简单粗暴,但能用。
⚠️ 踩坑预警:root.after() 是在主线程里执行回调的。如果 PLC 响应慢(比如网络延迟超过 500ms),界面会出现明显卡顿。数据量一大,这个问题会更突出。所以这个版本只适合快速验证,别直接上生产。
🤔 你是不是也遇到过这些情况?
在 WinForms 项目里需要展示一张折线图,翻遍了资料,发现要么是 WPF 的教程、要么是上古版本的 LiveCharts 1.x,对着文档折腾了半天,NuGet 包装上去控件工具箱里死活找不到,最后只能用 System.Windows.Forms.DataVisualization 凑合——渲染效果粗糙,动画没有,交互更别提了。
这种体验,相信写过 WinForms 数据面板的开发者都有过。
好消息是,LiveCharts 2(LiveCharts Core) 已经完整支持 WinForms,底层基于 SkiaSharp 渲染,性能和视觉效果比老版本提升了不止一个量级。本文从零开始,带你完成:
- ✅ LiveCharts 2 在 WinForms 中的完整环境搭建
- ✅ 第一张可运行的折线图
- ✅ 主题配置与中文字体适配(这个坑很多人踩)
- ✅ 常见报错与排查思路
字数不多,但每一步都经过实际验证,跟着做完,你的项目里就有一张真正能跑起来的图表。
🧱 先搞清楚:LiveCharts 2 和 1.x 的区别
很多人在搜索资料时会同时看到 LiveCharts 和 LiveCharts2,这两者不是同一个库,不能混用。
LiveCharts 1.x 已停止维护,底层依赖 WPF 渲染管线,在 WinForms 里用起来很别扭,控件也不稳定。LiveCharts 2 是作者 beto-rodriguez 重写的版本,核心渲染引擎换成了 SkiaSharp,跨平台能力大幅提升,同一套 API 可以跑在 WinForms、WPF、MAUI、Blazor 等几乎所有 .NET UI 框架上。
对 WinForms 开发者来说,最直观的变化是:
- 图表控件可以直接拖到设计器里
- 支持动画与实时数据刷新
- 渲染质量接近矢量图,缩放不失真
- NuGet 包按平台拆分,WinForms 有独立的包
LiveChartsCore.SkiaSharpView.WinForms
目前 LiveCharts 2 仍处于 RC(候选发布)阶段,安装时需要勾选"包括预发行版",这是很多人第一步就卡住的原因。
🛠️ 环境搭建:一步一步来
第一步:创建 WinForms 项目
打开 Visual Studio 2026,选择"创建新项目",模板选 Windows 窗体应用(注意不是 WPF,也不是控制台)。
项目名称随意,目标框架建议选 .NET 8.0。LiveCharts 2 向下兼容到 .NET Framework 4.6.2,如果你的老项目框架较低也没关系,但 .NET 8 的体验会更顺畅。
第二步:安装 NuGet 包
右键项目 → 管理 NuGet 程序包 → 搜索框输入:
LiveChartsCore.SkiaSharpView.WinForms
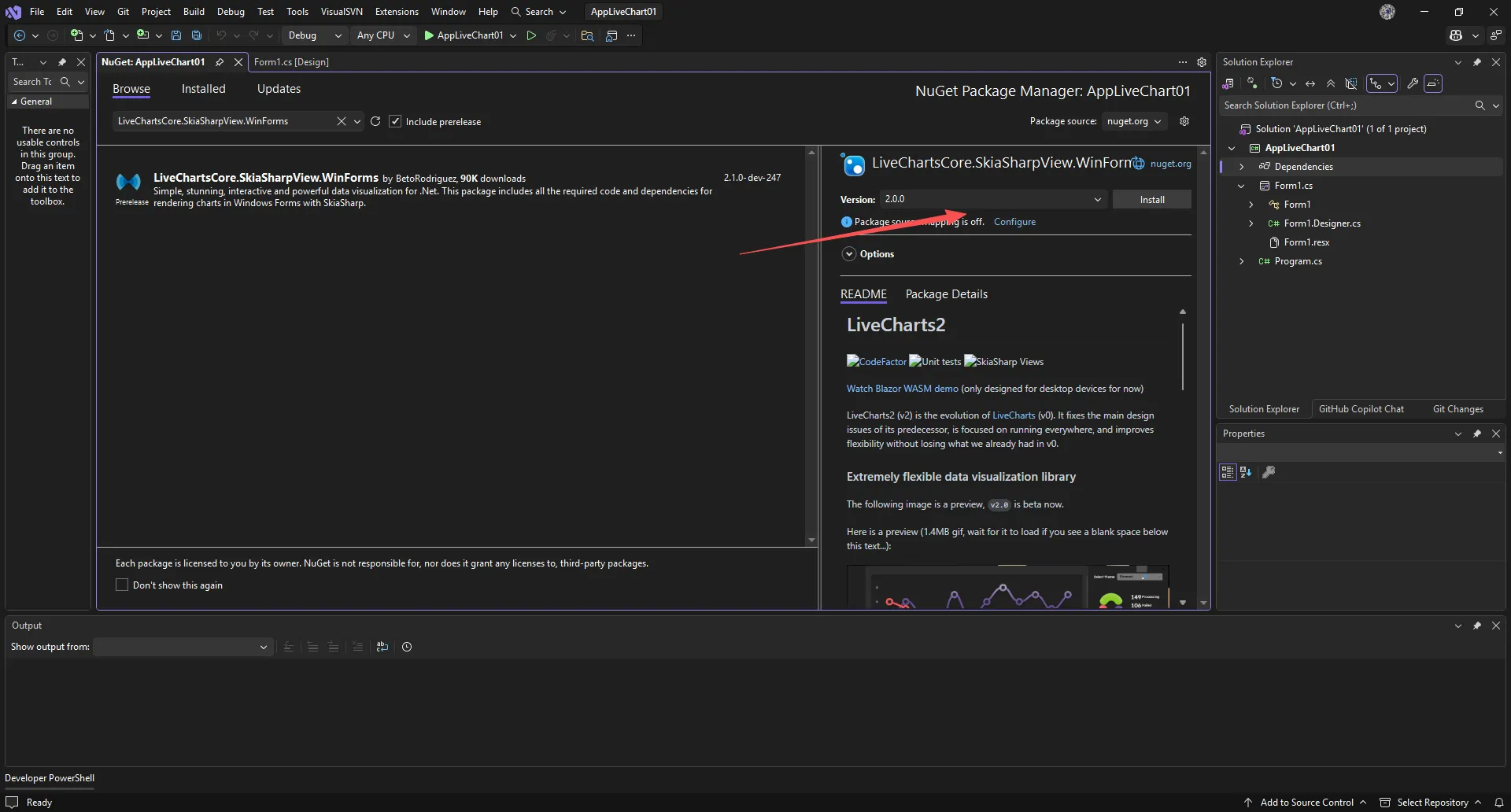
**关键操作:2.0我记得好几年了,终于正式版本有了,找到包后点击安装,Visual Studio 会自动拉取所有依赖项(包括 SkiaSharp 相关的底层库)。
如果你更喜欢命令行,在程序包管理器控制台执行:
powershellInstall-Package LiveChartsCore.SkiaSharpView.WinForms -IncludePrerelease
安装完成后,重新生成项目(Build → Rebuild Solution),然后打开工具箱,你应该能看到 CartesianChart、PieChart、GeoMap 等控件出现在工具箱列表里。
如果工具箱里没有出现控件,不要慌,这是个常见问题。关闭 VS,删除
.vs隐藏文件夹,重新打开项目再 Rebuild 一次,通常能解决。
第三步:拖控件到窗体
从工具箱找到 CartesianChart,直接拖到 Form1 设计器上。调整控件大小,让它占满窗体的大部分区域。
拖进去之后,控件的默认名称是 cartesianChart1,后面代码里会用到这个名字。
📊 第一张图表:折线图实战
最简实现
打开 Form1.cs 的代码视图,在构造函数里加几行代码:
csharpusing LiveChartsCore;
using LiveChartsCore.SkiaSharpView;
namespace AppLiveChart01
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// 设置折线图数据系列
cartesianChart1.Series = new ISeries[]
{
new LineSeries<double>
{
// 模拟一周内某接口的平均响应时间(单位:ms)
Values = new double[] { 120, 98, 135, 87, 110, 76, 95 },
Fill = null, // 不填充线下面积
Name = "响应时间 (ms)"
}
};
}
}
}
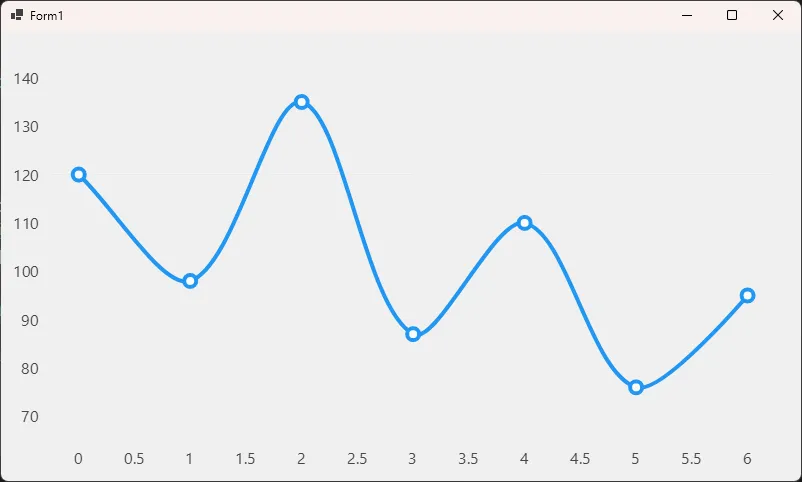
F5 运行,一张带动画的折线图就出来了。数据点会有平滑的入场动画,鼠标悬停时还有 Tooltip 弹出,这些都是默认行为,不需要额外写任何代码。
你有没有遇到过这样的尴尬?
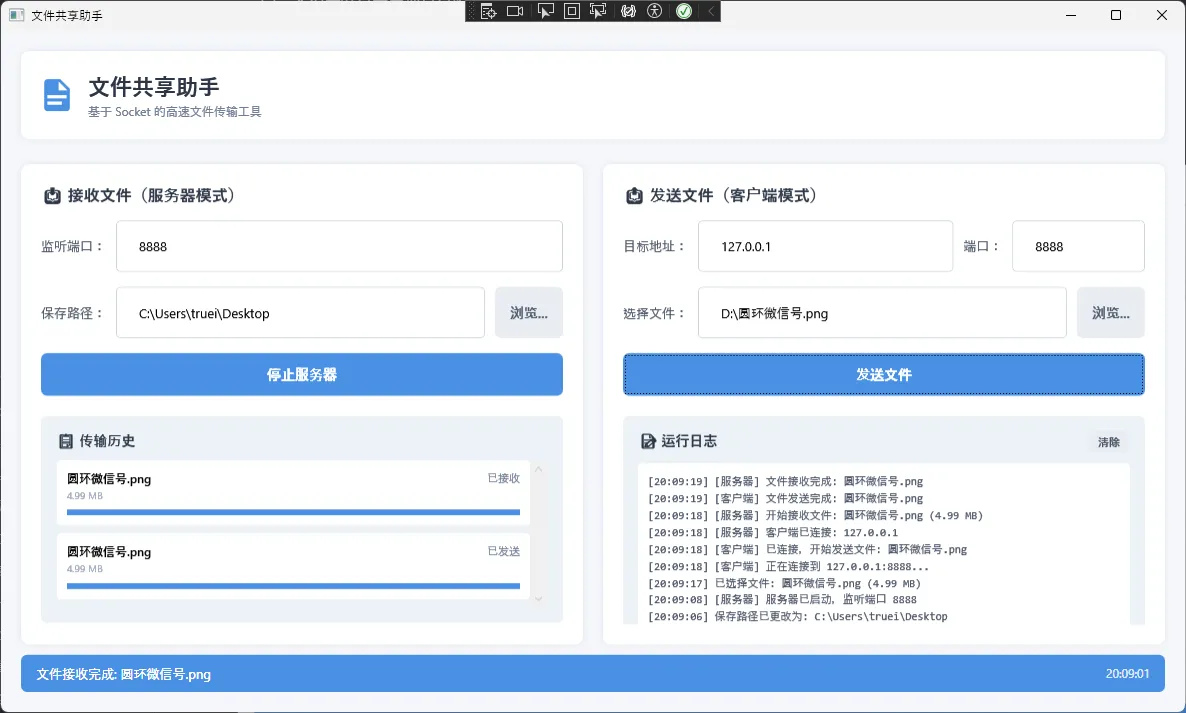
开发团队内部需要快速传输大文件,QQ传文件慢得要死,微信有大小限制,网盘又要登录账号...最后只能拿个U盘跑来跑去。这效率,简直让人抓狂!
更糟糕的是——很多开发者以为Socket编程很复杂,总是绕着走。但实际上,一个完整的文件传输应用,核心代码不到300行。今天咱们就从零开始,手把手搭建一个比QQ传文件还快的Socket文件传输工具。
你将收获什么?
- 掌握Socket网络编程的核心思路
- 学会WPF现代化UI设计套路
- 获得可直接商用的完整项目代码
- 理解高性能文件传输的底层原理
🎯 为什么Socket传输这么快?
先说个数据震撼你一下:
传统HTTP文件传输:平均速度15-25MB/s Socket直连传输:可达100MB/s+(局域网环境)
差距这么大的原因很简单——中间环节越少,速度越快。
HTTP传输就像寄快递:文件 → 打包 → 标签 → 分拣 → 运输 → 再分拣 → 派送 Socket直连像面对面递东西:文件 → 直接给你
这就是为什么很多企业内部都选择Socket方案的原因。
💡 技术架构全景图
咱们的文件传输工具采用经典的C/S架构:
┌─────────────────┐ ┌─────────────────┐ │ WPF客户端 │ Socket │ WPF服务端 │ │ ┌───────────┐ │ ◄─────► │ ┌───────────┐ │ │ │文件选择器│ │ │ │文件接收器│ │ │ └───────────┘ │ │ └───────────┘ │ │ ┌───────────┐ │ │ ┌───────────┐ │ │ │进度显示器│ │ │ │历史记录器│ │ │ └───────────┘ │ │ └───────────┘ │ └─────────────────┘ └─────────────────┘
核心优势:
- 同一个程序既是客户端又是服务端
- 支持双向传输(A→B,B→A都可以)
- 现代化UI,操作直观
先看一下效果
先说说这个问题有多烦
做工业软件这行,你迟早会遇到这种场景——
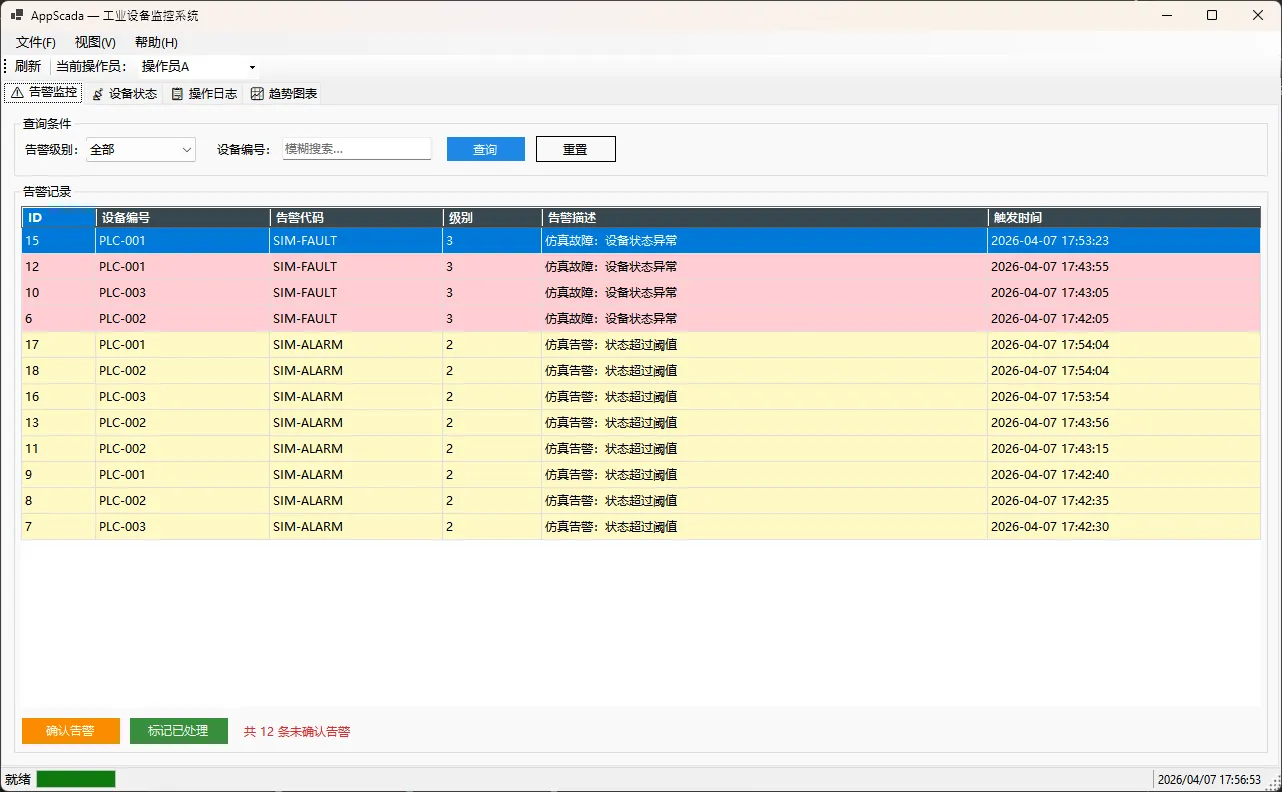
凌晨两点,某条产线的设备突然报警。操作员盯着屏幕,界面卡了三秒才刷新。日志窗口里一片空白。没人知道这个告警是什么时候触发的,也没人知道上一个操作是谁做的、做了什么。
这不是极端案例。这是我亲眼见过的真实现场。
问题的根源,往往不是硬件,不是网络,而是软件架构从一开始就没想清楚。告警逻辑、UI刷新、数据库写入全部塞在同一个线程里,互相阻塞。日志记录散落在各个按钮事件里,格式五花八门,查起来像在考古。
今天这篇文章,就聊聊我在一个基于C# WinForms的工业SCADA项目里,怎么把AlarmService和OperationLogger这两个核心模块从头设计清楚的。
先看效果
🏗️ 架构思路:三件事必须分开
在动手写代码之前,我强迫自己先想清楚三个问题:
谁负责触发告警?谁负责存储?谁负责展示?
这三件事,必须物理隔离。
很多项目死在这里——在按钮点击事件里直接写数据库,在数据库回调里直接刷新UI控件。看起来省事,实际上是在给自己挖坑。设备轮询线程一旦触发告警,UI线程被阻塞,整个界面冻住,操作员什么也干不了。
我的方案是这样的:
设备轮询线程 └── AlarmService.TriggerAlarmAsync() ├── 异步写入 SQLite(不阻塞) └── 触发事件 OnAlarmTriggered └── AlarmPanel 订阅(BeginInvoke 跨线程安全刷新)
三层完全解耦。轮询线程只管触发,数据库只管持久化,UI只管展示。任何一层出问题,不会拖垮其他层。
🤔 你是否也遇到过这样的困境?
单机Worker跑得好好的,业务量一上来就开始"喘气"——队列积压、内存告警、任务超时。加机器?代码根本没考虑分布式,改起来像拆房子重建。
这不是个例。在实际项目里,单机Worker的瓶颈往往不是代码写得烂,而是架构从一开始就没有为"扩展"留门。
我在一个订单处理系统里就踩过这个坑:单机峰值QPS撑到800就开始丢任务,加了两台机器却因为没有协调机制,同一批任务被重复处理了三遍,客诉直接打过来。
读完这篇文章,你将掌握:
- 为什么单机Worker在分布式场景下必然失效,以及根本原因在哪
- 基于Redis构建轻量级分布式管道的核心设计
- 三个渐进式落地方案,从改造成本最低的方案起步,逐步演进到生产级集群架构
🔍 问题深度剖析:单机Worker的三道墙
第一道墙:资源天花板
单机Worker的处理能力受限于单台服务器的CPU核心数、内存容量与网络带宽。以一个典型的图片处理Worker为例,单核处理一张图平均耗时120ms,8核机器理论并发上限约67张/秒。一旦业务峰值超过这个数字,队列就开始无限膨胀。
单机处理模型(测试环境:8核16G,.NET 8) 峰值吞吐:~67 tasks/s 队列积压临界点:500 tasks 内存压力点:任务堆积超过2000条时RSS增长约40%
第二道墙:单点故障
单机宕机 = 整个管道停摆。没有故障转移,没有任务重新投递,业务直接中断。这在金融、电商等对可用性要求高的场景里是不可接受的。
第三道墙:状态共享的缺失
多个Worker实例横向扩展时,最大的难题不是"怎么多跑几个进程",而是"怎么让它们协调工作"。没有共享状态层,就会出现:
- 重复消费:同一条任务被多个Worker同时拿到
- 饥饿问题:某些Worker空跑,另一些却积压
- 无法追踪进度:任务执行状态散落在各节点本地内存,无法汇总
这三道墙,是单机Worker走向分布式必须逐一击破的核心障碍。
💡 核心要点提炼:Redis为什么适合做管道基础
Redis在这个场景里扮演的不是"数据库",而是分布式协调层。它的几个特性天然契合Worker管道的需求:
原子操作保证:LPUSH/BRPOP等命令是原子的,多个Worker同时抢任务不会出现竞争条件,这是避免重复消费的基础。
阻塞式消费:BRPOP支持阻塞等待,Worker不需要轮询,节省CPU资源,延迟也更低(通常在1ms以内)。
Stream数据结构:Redis 5.0引入的XADD/XREADGROUP提供了消费者组语义,天然支持ACK确认、消息重投、消费进度追踪,是构建可靠管道的利器。
轻量级:相比Kafka、RabbitMQ,Redis的运维复杂度低得多,对中小团队极其友好。
🛠️ 解决方案设计:三个渐进式方案
方案一:基础版 — Redis List实现任务队列
这是改造成本最低的起点,适合已有单机Worker、需要快速水平扩展的场景。
核心思路:用Redis List替代本地内存队列,所有Worker实例共享同一个队列,通过BRPOP的原子性保证每条任务只被一个Worker消费。
csharpusing Microsoft.Extensions.Hosting;
using StackExchange.Redis;
using System;
using System.Collections.Generic;
using System.Text;
using System.Text.Json;
namespace AppWorkerRedis
{
public class MyTask
{
public string Id { get; set; } = Guid.NewGuid().ToString();
public string Name { get; set; } = string.Empty;
public string Payload { get; set; } = string.Empty;
public DateTime CreatedAt { get; set; } = DateTime.UtcNow;
}
// 任务生产者
public class TaskProducer
{
private readonly IDatabase _db;
private const string QueueKey = "worker:task:queue";
public TaskProducer(IConnectionMultiplexer redis)
{
_db = redis.GetDatabase();
}
public async Task EnqueueAsync<T>(T task) where T : class
{
var payload = JsonSerializer.Serialize(task);
// LPUSH 将任务推入队列头部
await _db.ListLeftPushAsync(QueueKey, payload);
}
}
// Worker消费者(可多实例部署)
public class TaskWorker : BackgroundService
{
private readonly IDatabase _db;
private const string QueueKey = "worker:task:queue";
private readonly TimeSpan _blockTimeout = TimeSpan.FromSeconds(5);
public TaskWorker(IConnectionMultiplexer redis)
{
_db = redis.GetDatabase();
}
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
// BRPOP 阻塞等待,原子性弹出,多实例安全
var result = await _db.ListRightPopAsync(QueueKey);
if (result.IsNull)
continue;
try
{
var task = JsonSerializer.Deserialize<MyTask>(result.ToString(), new JsonSerializerOptions { PropertyNameCaseInsensitive = true });
await ProcessAsync(task!, stoppingToken);
}
catch (Exception ex)
{
// 基础版:失败直接记录,不重试(方案三会解决这个问题)
Console.WriteLine($"[Worker] Task failed: {ex.Message}");
}
}
}
private async Task ProcessAsync(MyTask task, CancellationToken ct)
{
// 实际业务处理逻辑
await Task.Delay(100, ct); // 模拟处理耗时
Console.WriteLine($"[Worker] Processed task: {task.Id}");
}
}
}
这个方案的局限:BRPOP弹出任务后如果Worker崩溃,任务就丢了。对于不允许丢失的业务场景,需要升级到方案三。
