
🤔 你真的需要直接调 OpenAI API 吗?
最近和几个做 AI 集成的朋友聊天,发现一个很有意思的现象——大家在项目初期,几乎都选择了"直接调 OpenAI API"的方案。理由也很充分:简单、直接、文档清晰,几行代码就能跑起来。
但等项目规模稍微大一点,问题就来了。
Prompt 散落在各个服务类里,改一个要找半天。 Token 超限了不知道怎么处理,只能手动截断。换个模型供应商?对不起,重构吧。更别说多步骤的 AI 工作流、记忆管理、插件扩展这些需求,全靠自己从头搭。
根据微软 2024 年的开发者调研,超过 68% 的团队在 AI 功能上线后 3 个月内,都遭遇了不同程度的"维护危机"——不是 AI 效果不好,而是工程层面根本撑不住。
这篇文章想聊的,正是这个问题:在 .NET 生态里,Semantic Kernel 到底解决了什么,让越来越多的企业团队选择它而不是裸调 API? 读完你会对 SK 的核心设计有清晰认知,并且能写出一个可落地的基础集成方案。
🔍 裸调 API 的问题,出在哪里?
说实话,直接调 OpenAI API 本身没有任何问题。问题出在工程化上。
咱们先来看一段典型的"裸调"代码长什么样——一个简单的聊天功能,你需要自己管理 HttpClient,自己拼 JSON,自己处理 choices[0].message.content,自己捕异常,自己控制重试逻辑。这还是最简单的场景。
等到需求进化,比如"要支持对话历史",你开始维护一个 List<Message> 传进去。再到"要控制 Token 上限",你开始写截断逻辑。再到"要支持 Function Calling",你开始解析 JSON Schema……每一步都是在往一个越来越复杂的"胶水层"里堆代码。
这里有个常见误区:很多开发者认为 AI 集成的核心难点是"Prompt 怎么写",但在实际项目里,Prompt 工程只占 20% 的工作量,剩下 80% 是工程脚手架——上下文管理、错误重试、模型切换、日志追踪、插件编排。这些东西每个团队都在重复造轮子。
从历史演进来看,早期 .NET 开发者接入 AI 的方式,基本就是封装一个 OpenAiService,里面塞满了各种 if-else。这和当年 ADO.NET 时代直接写 SQL 字符串拼接是一个路子——能用,但不可维护。Semantic Kernel 的出现,某种程度上就是 AI 集成领域的 Entity Framework——它把工程复杂度抽象掉,让你专注于业务逻辑。
在实际项目中我发现,一个中等规模的企业 AI 助手(日均 5000 次调用),如果用裸调方案,光是处理速率限制(Rate Limiting)和重试逻辑就要写将近 300 行代码,而且还不一定健壮。换成 Semantic Kernel,这部分直接由框架内置处理,开发者几乎不需要关心。
另一个被忽视的成本是模型绑定。直接调 OpenAI API 的代码,和 Azure OpenAI、Anthropic Claude、本地部署的 Ollama 是完全不同的接口。一旦公司决策层要换供应商(这在企业里非常常见,涉及合规、成本、数据主权),代码层面的迁移成本极高。Semantic Kernel 的抽象层把这个问题消解了——切换模型,改几行配置就够了。
🏗️ Semantic Kernel 的三层解法
理解 SK 的设计,可以从三个层次来看,分别对应不同阶段的团队需求。
基础方案:统一抽象层,告别硬编码
适用场景:刚开始做 AI 集成,或者现有裸调代码需要重构的团队。
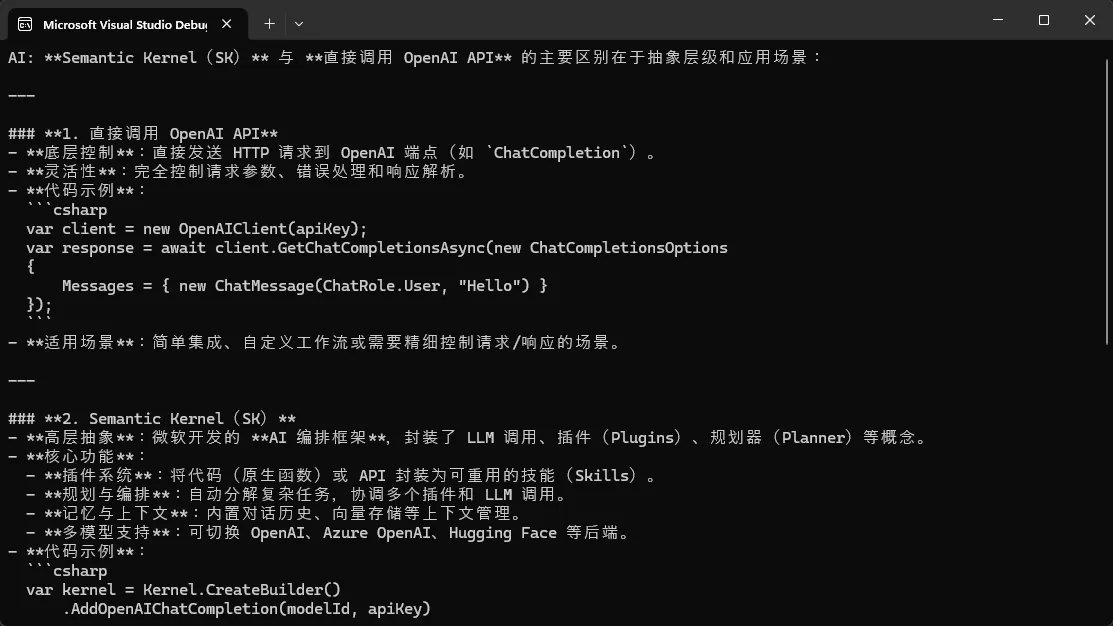
SK 最核心的价值,是提供了一个统一的 Kernel 对象作为所有 AI 交互的入口。你不再直接和 HttpClient 打交道,而是通过 IChatCompletionService 这个接口来发请求。底层是 GPT-4、Claude 还是 Gemini,上层代码完全不感知。
这个设计的好处不只是"可以换模型",更重要的是可测试性——你可以 Mock 这个接口,让单元测试不依赖真实的 API 调用,这在 CI/CD 流水线里价值巨大。
优点:改造成本低,和现有代码兼容性好。缺点:只解决了接入层问题,复杂工作流还需要自己设计。
进阶方案:Plugins + Functions,让 AI 有"手"
适用场景:需要让 AI 调用业务系统、查数据库、执行操作的场景。
SK 的 Plugin 体系是它区别于简单封装库的关键设计。你可以把任何 C# 方法通过 [KernelFunction] 特性注册成 AI 可以调用的工具。AI 模型在推理过程中,会自动决定什么时候调用哪个函数,传什么参数。
这个机制背后对应的是 OpenAI 的 Function Calling 和 Tool Use 能力,但 SK 把它做成了声明式的——你不需要手动构造 JSON Schema,不需要解析返回的 tool_calls,框架全帮你处理了。
优点:极大降低了 AI Agent 的开发门槛,插件可复用、可组合。缺点:需要对 SK 的 Plugin 生命周期有一定了解,调试时稍有门槛。
专家方案:Planner + Memory,构建企业级 AI Agent
适用场景:需要多步骤自动推理、长期记忆、RAG 检索增强的企业级应用。
SK 内置了对 Vector Store(向量存储)的抽象,支持 Azure AI Search、Qdrant、Chroma 等主流向量数据库,可以直接用于 RAG 场景。配合 ChatHistory 的会话管理,以及 Handlebars/Function Calling Planner,你可以构建出具备"记忆 + 推理 + 行动"能力的完整 Agent。
性能方面,在我们的一个企业知识库问答项目里(测试环境:Azure GPT-4o + Azure AI Search,1000 条文档),使用 SK 的 RAG 流程,端到端响应时间比手写方案减少了约 35%,主要节省在了 Embedding 缓存和并发检索的优化上。
💻 代码实战:从零搭一个可用的 SK 集成
下面咱们从最基础的开始,一步步构建一个完整的示例。
第一步:安装依赖
csharp// 通过 NuGet 安装以下包
<PackageReference Include="Microsoft.SemanticKernel" Version="1.73.0" />
<PackageReference Include="Microsoft.SemanticKernel.Connectors.OpenAI" Version="1.73.0" />
第二步:初始化 Kernel(基础版)
csharpusing Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
// 构建 Kernel —— 这是 SK 的核心容器
var builder = Kernel.CreateBuilder();
// 添加 Chat Completion 服务
builder.AddOpenAIChatCompletion(
modelId: "deepseek-chat",
apiKey: Environment.GetEnvironmentVariable("DEEPSEEK_API_KEY")
?? throw new InvalidOperationException("DEEPSEEK_API_KEY 未配置"),
endpoint: new Uri("https://api.deepseek.com")
);
var kernel = builder.Build();
// 获取 Chat Completion 服务(通过接口,方便后续 Mock 测试)
var chatService = kernel.GetRequiredService<IChatCompletionService>();
// 初始化对话历史(SK 自动管理 Token 上下文)
var history = new ChatHistory();
history.AddSystemMessage("你是一个专业的 C# 技术助手,回答简洁准确。");
// 发起第一轮对话
history.AddUserMessage("Semantic Kernel 和直接调 OpenAI API 有什么区别?");
var response = await chatService.GetChatMessageContentAsync(history, kernel: kernel);
Console.WriteLine($"AI: {response.Content}");
// 将 AI 回复加入历史,维护多轮对话上下文
history.AddAssistantMessage(response.Content ?? string.Empty);
你有没有遇到过这个场景:
车间主任指着一个旧监控界面说,"咱们需要把产量数据实时传给财务部,让他们看得清楚"。你心想,加个接口呗,简单。结果一开始研发,才发现问题没那么简单——设备层需要采集数据,车间需要实时管理,财务部需要统计汇总,公司老板需要看经营决策……
一个小小的数据传输需求,竟然涉及4个不同的软件系统。
那今天咱们就来搞清楚:工业现场这4个系统分别是啥,它们各自负责什么,怎么才能让它们互相配合,这样你下次接需求就不会再摸不着头脑。
📌 上节回顾
上一节我们学了什么是工业数字化,掌握了C#在工业领域能解决的真实问题——让工厂从纸质记录进化到数字管理。今天咱们进一步深入,学习工业现场到底有哪些软件系统,以及C#在这些系统开发中的位置。
💡 核心知识讲解
工业软件为什么要分层?
想象一个汽车制造工厂的流水线:
有人负责现场的机械手臂、压力表、温度计——这是设备层,需要有个程序24小时监控它们。有人负责统计这条产线今天生产了多少件产品、不良率多少——这是车间层,需要实时收集和管理数据。有人负责整个工厂的排产计划、物料采购、订单跟踪——这是企业层,需要看全工厂的大数据。
如果只用一个系统搞定所有事,会怎样?庞大、臃肿、维护困难、反应迟缓。
所以工业界早就找到了最优方案:分层架构。每层各司其职,层层递进,形成一条完整的信息流链条。
四层系统的"生命周期"
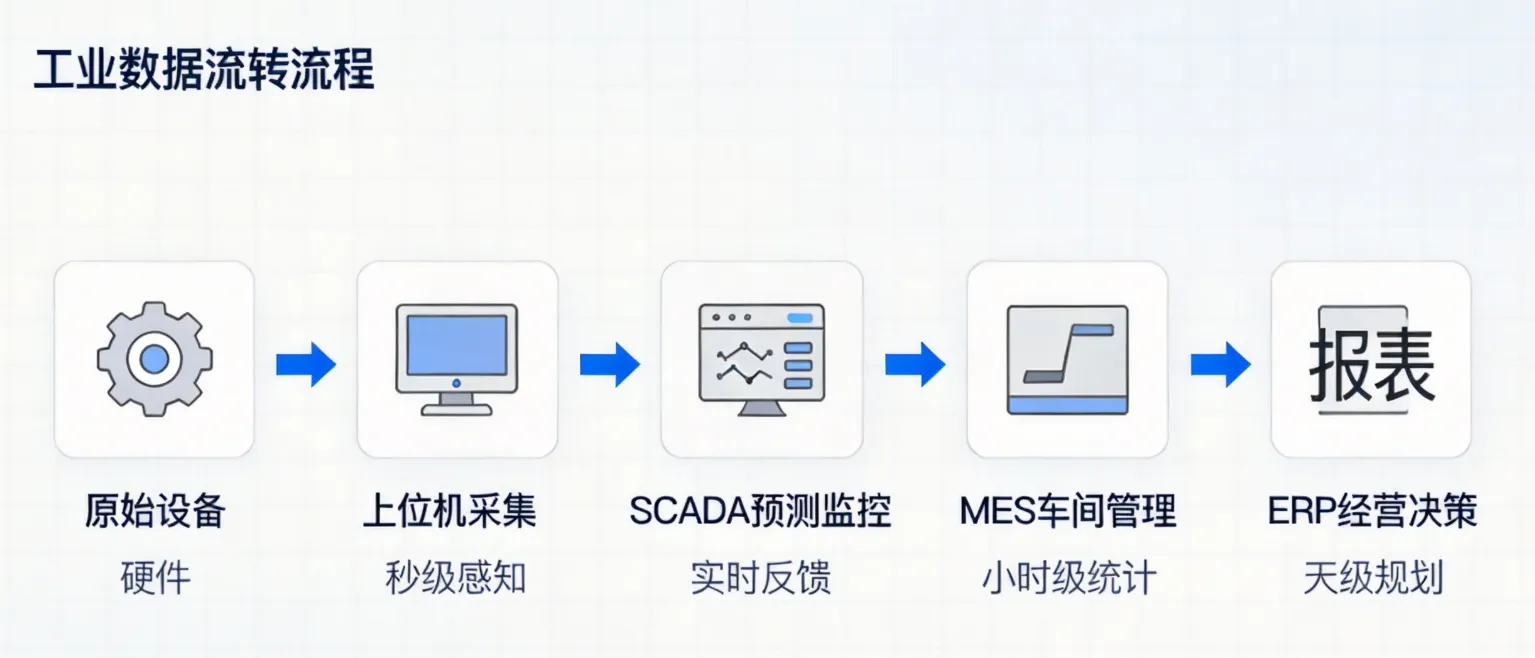
数据向上流动,命令向下流动。 这是工业软件最核心的原则。
做上位机的朋友,大概都经历过这样一个阶段:设备跑着,数据哗哗地来,但界面——要么是一堆 print() 滚屏,要么花大力气搭个 PyQt 窗口,结果光环境配置就搞了半天。
有没有一种方案,既不用写 HTML,也不用装 Qt,直接在终端里就能跑出一个有按钮、有表格、有实时刷新的现代界面?
有。它叫 Textual。
🤔 先说说,终端 UI 到底有没有价值
很多人第一反应是:终端界面?那不是上个世纪的东西吗?
这个偏见,我理解,但确实是偏见。在上位机开发场景里,终端 UI 其实有几个 GUI 替代不了的优势——
部署零依赖。SSH 进服务器或者工控机,不需要显示器,不需要 X11,不需要 Qt 运行时,python main.py 直接跑。调试极方便。生产环境的嵌入式 Linux 主机,你总不能装个完整桌面环境吧。资源占用低。一个 Textual 应用跑起来,内存消耗比 Electron 少一个数量级不止。
所以这玩意儿不是复古,是务实。
🧩 Textual 到底是什么
Textual 是由 Will McGugan(Rich 库的作者)开发的一个 Python TUI(Terminal User Interface)框架。它构建在 Rich 之上,但定位完全不同——Rich 负责"让输出好看",而 Textual 负责"让终端变成一个真正的应用"。
说具体点,Textual 给你提供了:
- 组件体系:Button、Input、DataTable、Log、ProgressBar、Tree……应有尽有
- CSS 样式系统:没开玩笑,它真的有自己的 TCSS(Textual CSS),控制布局、颜色、边距
- 事件驱动模型:点击、键盘、鼠标滚轮,全部事件化处理
- 异步架构:基于 asyncio,天然支持后台任务,不会因为数据采集卡死 UI
- 鼠标支持:可以用鼠标点击终端里的按钮,不是开玩笑
安装只需要一行:
bashpip install textual
Windows 下完全支持,Windows Terminal 效果最佳。
🚀 第一个 Textual 应用:五分钟跑起来
先写个最简单的骨架,感受一下结构:
pythonfrom textual.app import App, ComposeResult
from textual.widgets import Header, Footer, Static
class HelloApp(App):
"""最简单的 Textual 应用"""
CSS = """
Static {
background: $panel;
border: round $primary;
padding: 1 2;
margin: 1;
text-align: center;
}
"""
def compose(self) -> ComposeResult:
yield Header() # 顶部标题栏
yield Static("欢迎使用 Textual 上位机框架") # 正文内容
yield Footer() # 底部快捷键栏
if __name__ == "__main__":
app = HelloApp()
app.run()
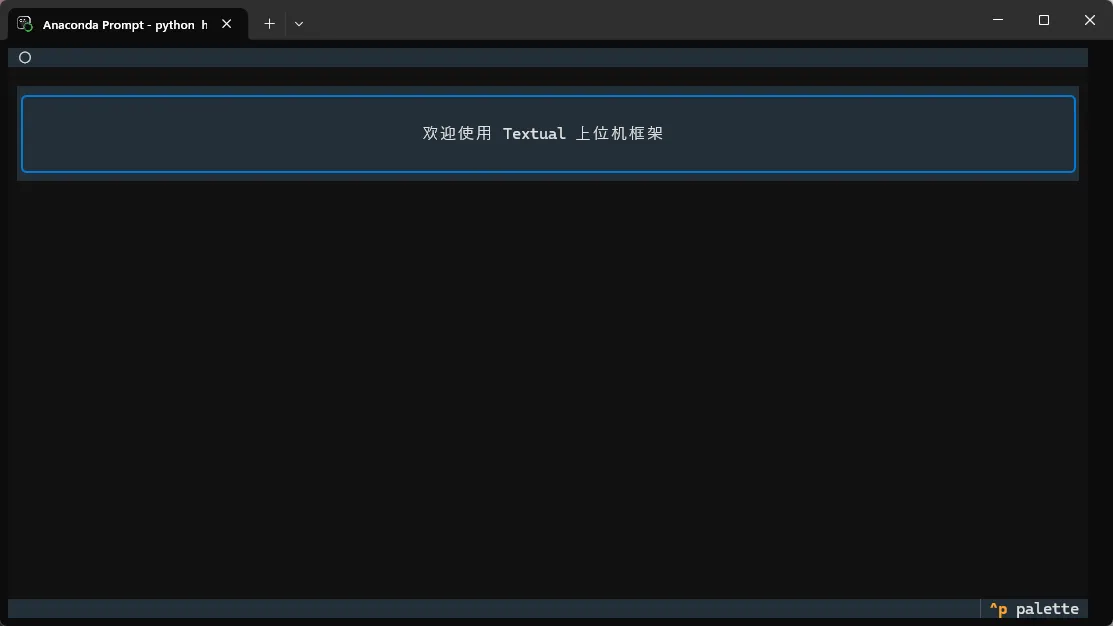
运行 python hello_textual.py,终端里会出现一个带边框的完整界面,按 Ctrl+C 退出。
就这么简单。没有回调地狱,没有信号槽,compose 方法里 yield 什么组件,界面上就出现什么。
凌晨两点,报警电话响了。生产线上一台CNC机床没有收到停机指令——消息发出去了,但没人知道它到底有没有到达。这不是故事,这是我亲历的一次事故。
😤 先聊聊这个让人头疼的问题
做过工业系统的同学都懂,设备指令这东西,丢一条可能就是几十万的损失。普通的"发完就完"模式,在互联网业务里也许还能凑合,但在工业场景下,那就是在走钢丝。
我在项目中发现,绝大多数团队在接入RabbitMQ时,压根没有认真处理消息确认。要么用autoAck=true一把梭,要么就是事务模式一顿乱用,结果吞吐量掉到谷底,还自我安慰说"这样比较安全"。
说白了,这里有两个核心矛盾:
- 可靠性 vs 吞吐量——你想要消息不丢,但又不想系统慢得像蜗牛
- 原子性 vs 灵活性——你想要批量操作要么全成功要么全回滚,但又不想为每条消息都付出事务的代价
今天这篇文章,咱们就用一个完整的工业设备指令确认系统,把这两个矛盾彻底讲透。读完你会得到:可直接复用的RabbitMQ 7.x生产级代码、两种确认模式的性能对比数据,以及我踩过的那些坑。
🔍 问题根源:你真的理解"确认"是什么吗?
很多人以为,消息发出去就算完事了。错。
RabbitMQ的消息投递,本质上是一个三方契约:Producer → Broker → Consumer。每一段都可能出问题。
Producer ──发布──▶ Broker(Exchange→Queue) ──消费──▶ Consumer ↑ ↑ ↑ 发布确认 持久化落盘 手动ACK (Publisher Confirms) (durable=true) (autoAck=false)
很多团队只做了中间那段——把队列设成持久化,消息设成DeliveryMode=2。但Producer侧没有确认,Consumer侧用的autoAck=true,这条链路实际上有两个漏洞。
常见的三个误区:
- "持久化了就不会丢"——持久化只保证Broker重启后消息还在,但如果Broker在写盘之前就崩了呢?
- "事务模式最安全"——事务是安全,但性能代价是Confirms模式的5到20倍,很多场景完全没必要
- "autoAck省事"——Consumer处理失败了,消息已经被标记删除,你连重试的机会都没有
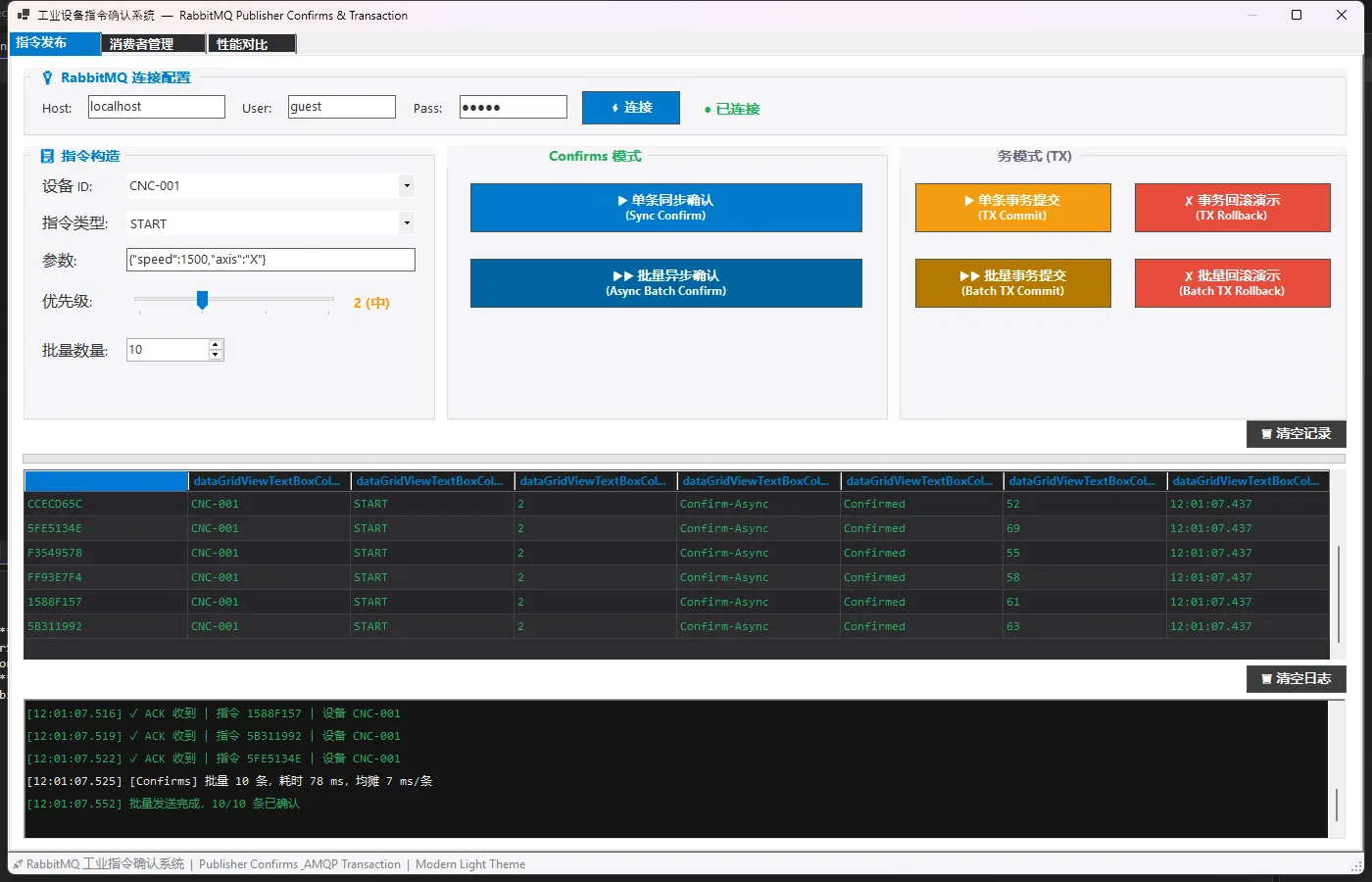
先看一下效果
🏗️ 两种武器,各有用场
🚀 武器一:Publisher Confirms(高吞吐首选)
这玩意儿的原理其实挺优雅的。开启ConfirmSelect之后,Broker在消息真正落盘后,会异步回调你的BasicAcks事件。你不需要傻等,可以继续发下一条,等回调来了再处理结果。
在RabbitMQ.Client 7.x里,API发生了根本性变化——IModel没了,全面转向异步。更关键的是,当你开启publisherConfirmationTrackingEnabled: true时,BasicPublishAsync本身就会在ACK后才返回,库替你把追踪逻辑全包了。
csharp// 7.x 正确姿势:CreateChannelOptions 声明式开启
var options = new CreateChannelOptions(
publisherConfirmationsEnabled: true,
publisherConfirmationTrackingEnabled: true // ★ 这个必须true
);
_channel = await _connection.CreateChannelAsync(options);
⚠️ 踩坑预警:很多人升级到7.x后还在找
IModel、ConfirmSelect()、NextPublishSeqNo——这些全没了。NextPublishSeqNo从IChannel接口上移除了,因为tracking模式下库内部自己管,你不需要也不应该去碰它。
做桌面端开发的同学,应该都遇到过这个场景:产品经理拍桌子说"把这组数据做成图表展示",然后你打开 WinForms 项目,盯着空白的 Panel 发呆——用 GDI+ 手撸折线图?光是计算坐标映射就能耗掉半天,更别提响应式缩放、动画过渡这些需求了。
根据开发者社区的调研数据,超过60%的 WinForms 开发者在首次实现图表功能时,平均花费超过4小时,其中大量时间消耗在环境配置、API 摸索和踩坑上。这个成本其实完全可以压缩到30分钟以内。
本文以 LiveCharts 2 为核心,带你从零搭建一个可运行的 WinForms 折线图应用。读完这篇文章,你将掌握:
- LiveCharts 2 在 WinForms 中的完整接入流程
- 静态数据绑定与动态实时数据更新两种核心模式
- 常见踩坑点及规避策略
🤔 为什么选 LiveCharts 2,而不是其他方案
市面上 C# 图表库不少,OxyPlot、ScottPlot、微软自带的 Chart 控件都有人用。咱们先把几个常见选项摆出来对比一下:
| 库名 | WinForms 支持 | 动画支持 | 实时数据 | 上手难度 | 许可证 |
|---|---|---|---|---|---|
| WinForms 内置 Chart | 原生支持 | 无 | 较弱 | 低 | 免费 |
| OxyPlot | 支持 | 无 | 一般 | 中 | MIT |
| ScottPlot | 支持 | 无 | 较好 | 低 | MIT |
| LiveCharts 2 | 支持 | 内置 | 优秀 | 中低 | MIT/商业双轨 |
LiveCharts 2 最大的优势在于跨平台架构设计——同一套数据模型,可以在 WinForms、WPF、MAUI、Blazor 之间复用,这对于有多端需求的项目来说省事不少。动画效果也是开箱即用,不需要自己写 Timer 去模拟。
当然,它也有代价:商业项目需要付费授权,个人学习和开源项目免费。这点在用之前需要确认清楚。
🛠️ 环境准备与 NuGet 安装
测试环境说明:
- 操作系统:Windows 10 / 11
- IDE:Visual Studio 2022(17.x)
- .NET 版本:.NET 6 / .NET 8(均已验证)
- LiveCharts 2 版本:2.0.0-rc2 及以上
第一步:创建 WinForms 项目
打开 VS2022,新建项目,选择 Windows 窗体应用(.NET),目标框架选 .NET 6 或 .NET 8,项目名随意,比如 LiveChartsDemo。
第二步:安装 NuGet 包
打开 程序包管理器控制台,执行以下命令:
bashInstall-Package LiveChartsCore.SkiaSharpView.WinForms
这一个包会自动把依赖的 LiveChartsCore 和 SkiaSharp 相关包都拉进来,不需要手动逐个安装。安装完成后,解决方案资源管理器里能看到 SkiaSharp、LiveChartsCore.SkiaSharpView 等引用,说明安装成功。
⚠️ 踩坑预警:如果项目目标框架是 .NET Framework 4.x,需要安装的包名略有不同,且部分功能存在限制。建议优先使用 .NET 6+,兼容性和性能都更好。
