
遇到过一个让人头疼的问题:高峰期API响应慢得像老牛拉车,排查后发现JSON序列化竟然占了30%的CPU时间!当时项目里用的是老牌的Newtonsoft.Json,虽然功能强大,但在高并发场景下确实有点吃不消。
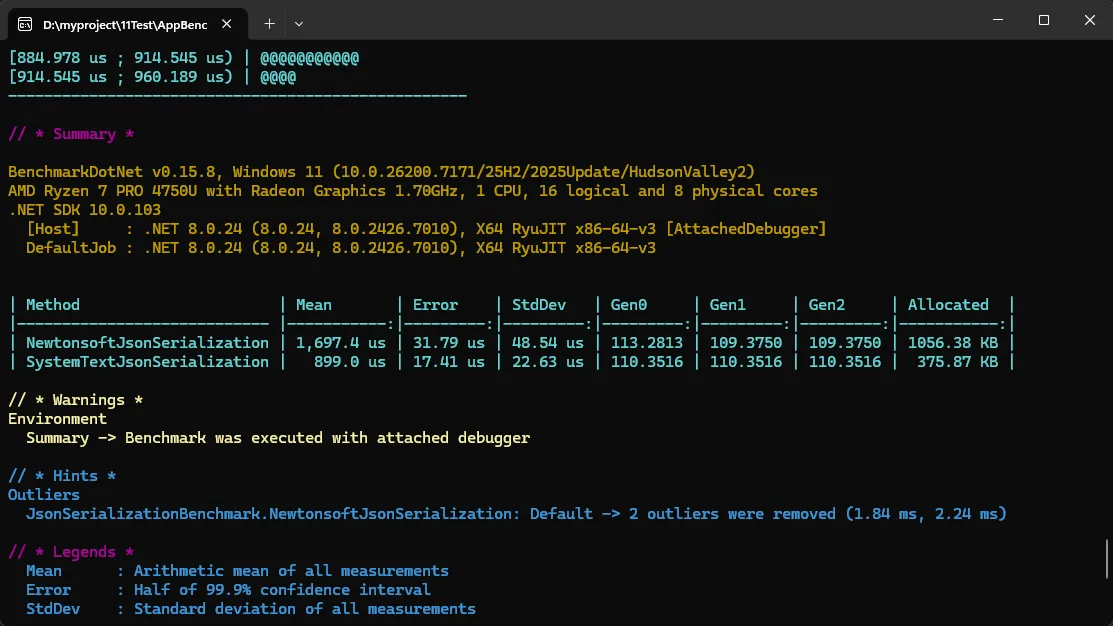
后来切换到 System.Text.Json 后,序列化性能提升了 2-3倍,内存分配减少了 40% 左右(基于. NET 6测试环境,10万次序列化操作)。这篇文章咱们就聊聊这个微软官方钦定的JSON库,它不仅仅是"又一个JSON库"那么简单。
读完本文你能收获:
- 掌握System.Text.Json的核心用法与配置技巧
- 学会编写自定义转换器解决复杂场景
- 获得3个可直接落地的性能优化方案
- 避开95%开发者会踩的常见坑
🔍 为什么要关注 System.Text.Json?
📊 先看一组真实数据对比
我在本地做了个简单测试(环境:. NET 8, Release模式):
⚠️ 常见的三个误解
很多同学跟我说过类似的疑虑,咱们得先破除这些误区:
-
误解一:"功能没Newtonsoft全"
确实,某些特殊场景(比如DataSet序列化)确实支持不够完善,但80%的常规需求都能覆盖,而且微软在持续更新。 -
误解二:"迁移成本太高"
其实大部分代码改动就是换个命名空间,核心逻辑基本不动。我团队去年迁移了一个20万行的项目,实际改动代码不到300行。 -
误解三:"只适合新项目"
老项目也能渐进式迁移,两个库可以共存。我见过不少项目是先把性能敏感模块(比如日志、缓存)换成Text.Json,然后逐步扩大范围。
💡 核心知识点拆解
🎯 三种序列化模式的选择
System.Text.Json提供了三种主要方式,每种都有最佳适用场景:
- JsonSerializer(反射模式):快速开发,性能中等
- JsonSerializerOptions(配置优化):平衡灵活性与性能
- Source Generator(编译时生成):极致性能,零反射
我的建议是:原型阶段用反射,生产环境上Source Generator。就像开车,先学自动挡,熟练了再开手动挡追求极致控制。
🔑 必须掌握的配置选项
这几个配置选项在实战中用得最多,我按使用频率排个序:
csharpvar options = new JsonSerializerOptions
{
// 🔥 使用频率Top1:属性命名策略(前端对接必备)
PropertyNamingPolicy = JsonNamingPolicy.CamelCase,
// 🔥 Top2:美化输出(调试神器,生产环境记得关)
WriteIndented = true,
// 🔥 Top3:忽略null值(减少传输体积)
DefaultIgnoreCondition = JsonIgnoreCondition.WhenWritingNull,
// 🔥 Top4:允许尾随逗号(兼容手写JSON)
AllowTrailingCommas = true,
// 🔥 Top5:大小写不敏感(容错处理)
PropertyNameCaseInsensitive = true
};
写了这么多年代码,我发现一个有趣的现象——很多程序员在面对复杂UI渲染时,第一反应都是"能跑就行"。
但现实很骨感。当你的工业监控系统需要同时显示200+设备精灵时,用户界面开始变成幻灯片。鼠标拖拽一个图标,整个屏幕卡顿2秒。这种体验,说是"工业4.0"都觉得心虚。
今天咱们聊一个"狠活"——如何用C#构建一个真正专业的工业精灵渲染引擎。不是那种拖控件的玩具,而是能在60FPS下流畅运行数百个复杂图形的硬核方案。
这篇文章你能收获什么?
- 分层渲染架构的底层设计逻辑
- 离屏缓冲技术的实际应用
- SkiaSharp在工业场景下的性能调优
- 完整的可运行项目代码(已开源)
🚀 传统渲染方式为什么这么慢?
问题的根源:重复劳动
大部分开发者的渲染思路是这样的:
csharp// ❌ 传统做法:每帧都重画所有内容
private void OnPaint(PaintEventArgs e)
{
// 清空画布
e.Graphics.Clear(Color.White);
// 遍历所有精灵,逐个绘制
foreach(var sprite in sprites)
{
DrawComplexShape(e.Graphics, sprite); // 每帧都重新计算复杂图形
DrawShadow(e.Graphics, sprite); // 重复绘制阴影效果
DrawLabel(e.Graphics, sprite); // 重新渲染文字
}
}
问题出在哪里?
想象一下,你有100个设备图标。即使只移动其中1个,传统方式也要把所有100个图标全部重新绘制一遍。这就像为了换个灯泡,把整栋楼的电都断了重接。
更要命的是,工业设备的图形往往很复杂——渐变填充、阴影效果、管道连接线...每个图标的绘制成本都不低。
数据说话:性能差距有多大?
我做过一个简单测试:
- 传统方式:100个复杂图标,帧率跌到15FPS
- 优化后方案:同样100个图标,稳定60FPS,CPU占用降低80%
这就是架构级别的优化威力。
👨💻先看效果
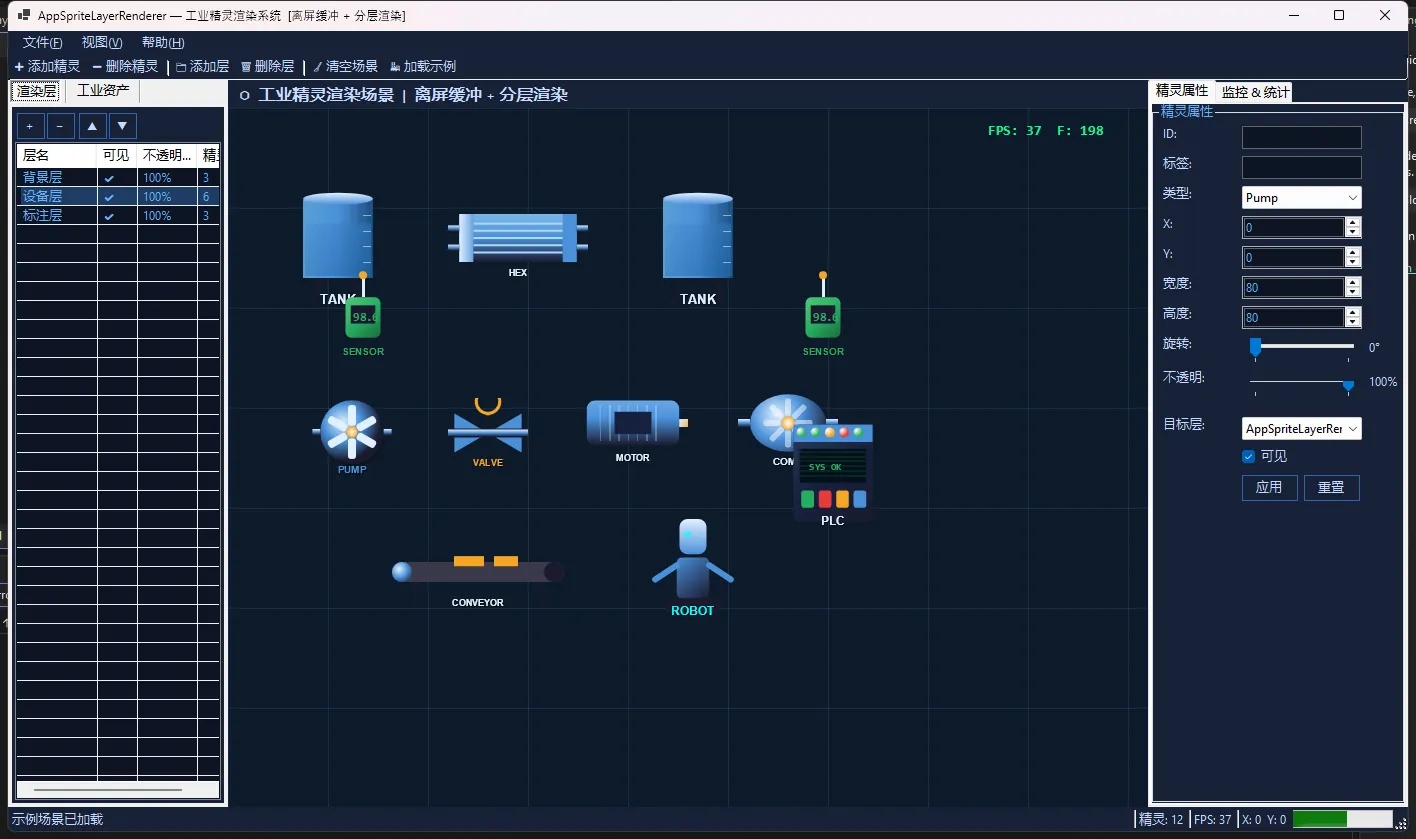
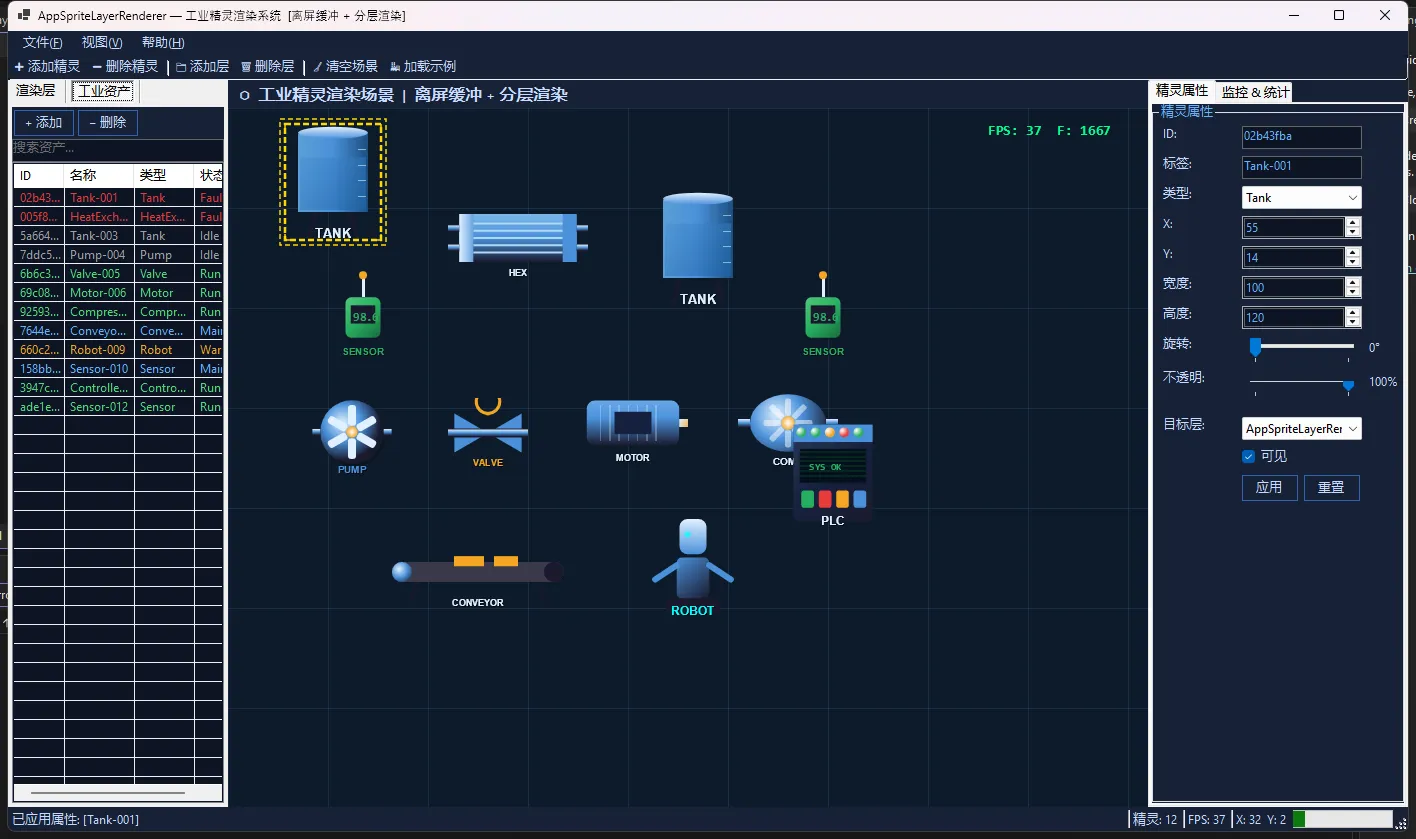
🎯 分层渲染:工业级解决方案
核心思想:分而治之
专业的渲染引擎都遵循一个原则——分层缓冲,按需更新。
csharp/// <summary>
/// 三层缓冲架构
/// </summary>
public class LayeredRenderEngine
{
// 第一层:精灵级别的离屏缓冲
private Dictionary<string, SKBitmap> _spriteBuffers = new();
// 第二层:图层级别的合成缓冲
private Dictionary<string, SKBitmap> _layerBuffers = new();
// 第三层:最终输出缓冲
private SKBitmap _finalBuffer;
}
为什么要这样设计?
工业场景有个特点:设备布局相对稳定,但状态变化频繁。比如一个泵的位置可能一天都不会变,但它的运行状态(温度、压力)每秒都在更新。
分层渲染就是为了应对这种"局部变化,整体稳定"的特性。
🤔 你的 Tkinter 代码,是不是长这样?
打开你三个月前写的那个 Tkinter 小工具——是不是一个文件里密密麻麻塞了八百行?Button 的回调函数里直接查数据库,Label 更新逻辑和业务计算混在同一个函数里,改一个需求要在代码里上下翻三遍才能找到对应的位置。
这不是你的问题。Tkinter 的官方示例本来就是这么教的。但项目一旦长大,这种写法的代价会让你怀疑人生。
我在一个工控项目里见过一个 main.py,2400 行,没有任何分层,所有逻辑全堆在 App 类里。新来的同事看了两眼,直接说"我重写一个"——然后又写成了一样的结构。
根本原因只有一个:没有架构意识。
今天咱们就来聊聊怎么用 MVC 模式把 Tkinter 项目彻底整理清楚。不是纸上谈兵,是带着完整可跑的代码,一步一步来。
🧱 MVC 到底是个什么东西?
Model-View-Controller,三个词,三个职责。
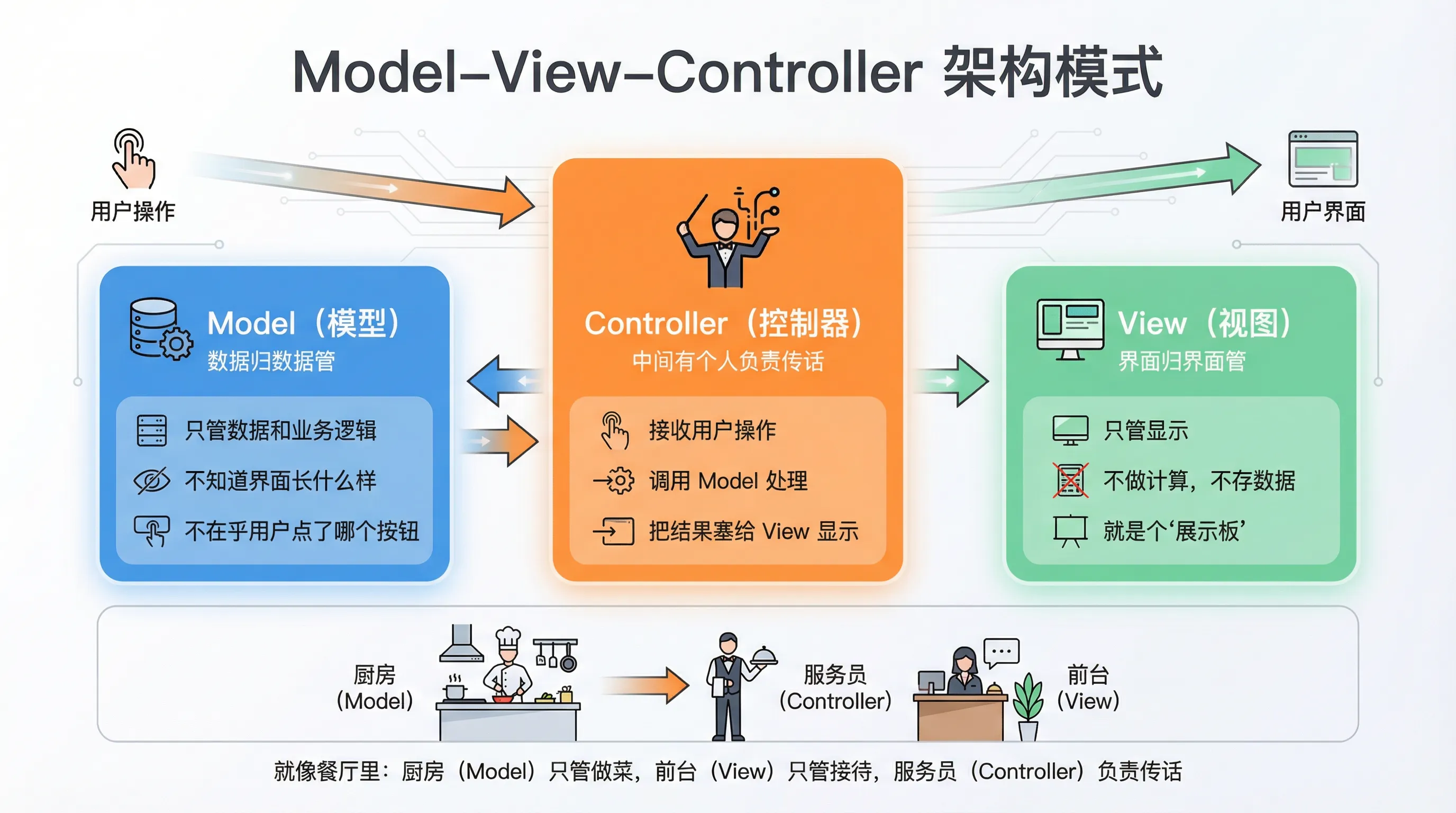
很多人第一次听到这个名字觉得很唬人,其实用一句大白话就能说清楚:数据归数据管,界面归界面管,中间有个人负责传话。
- Model(模型):只管数据和业务逻辑。它不知道界面长什么样,也不在乎用户点了哪个按钮。
- View(视图):只管显示。它不做计算,不存数据,就是个"展示板"。
- Controller(控制器):负责接收用户操作,调用 Model 处理,然后把结果塞给 View 显示。
三者的关系是单向的,或者说是有边界的。这个边界,就是架构的价值所在。
用一个比喻来说:餐厅里,厨房(Model)只管做菜,不管谁来吃;前台(View)只管接待客人,不管菜怎么做;服务员(Controller)负责把客人的点单传给厨房,再把菜端上桌。三个角色各司其职,换一个厨师不影响前台,换一套界面不影响业务逻辑。
本文面向有一定 C#/.NET 基础、正在接触工业数字化项目的开发者,聚焦离散制造车间中常见的四类现场信号类型,从业务含义到数据库设计再到代码实现,完整梳理一套可落地的映射方案。
一、问题引入
在我参与的一个汽车零部件工厂数字化项目中,现场有一台 PLC 通过 OPC-UA 向上位机推送数据。负责对接的开发同事把所有采集点一股脑存进了一张表,字段只有三个:point_name、value、timestamp。
上线后第一周,工艺工程师来反馈:"你们系统里设备运行状态怎么是 0.9997?设备要么开要么关,哪来的小数?"
开发同事一脸茫然——他不知道这个点位其实是一个 AI(模拟量输入)信号,采集的是主轴电流,单位安培,而不是开关状态。他把所有信号都当成了"数值",完全没有区分信号类型与业务含义。
这个问题在项目现场极其普遍。很多转行工业软件的开发者,在面对 DI/DO/AI/AO 这四类信号时,第一反应是"不就是读个值嘛"——但实际上,信号类型不同,业务语义不同,存储策略不同,处理逻辑也完全不同。
一旦混淆,轻则数据展示错误,重则触发错误报警、影响生产决策,甚至导致设备误动作。
二、经验分析
四类信号的本质区别
先把概念说清楚,这是后续一切设计的基础。
| 信号类型 | 全称 | 方向 | 值域 | 典型业务含义 |
|---|---|---|---|---|
| DI | Digital Input(数字量输入) | 设备 → 系统 | 0 / 1 | 按钮状态、传感器触发、门磁开关 |
| DO | Digital Output(数字量输出) | 系统 → 设备 | 0 / 1 | 继电器控制、指示灯、电磁阀 |
| AI | Analog Input(模拟量输入) | 设备 → 系统 | 连续浮点 | 温度、压力、电流、转速 |
| AO | Analog Output(模拟量输出) | 系统 → 设备 | 连续浮点 | 变频器频率设定、阀门开度指令 |
方向是第一个关键维度。DI 和 AI 是"读",DO 和 AO 是"写"。很多开发者在设计接口时忽略了方向,把所有点位都设计成可读可写,导致系统误写了不该写的点位,造成安全隐患。
值域是第二个关键维度。数字量只有 0/1,业务上对应"状态翻转";模拟量是连续值,业务上对应"工艺参数监控"。两者的存储频率、报警逻辑、历史查询方式都完全不同。
常见的错误做法
错误一:用统一的 value VARCHAR 字段存所有信号。
这看起来灵活,实际上丧失了类型约束,数值计算时还需要在代码里强制转换,极易出错。
错误二:DI/DO 用浮点数存储。 0.000000 和 1.000000 在数据库里看起来没问题,但一旦涉及"状态变化次数统计"或"边沿触发检测",浮点比较会带来精度问题。
错误三:所有信号用相同的采集频率。 AI 信号(如温度)可能 1 秒采一次,DI 信号(如急停按钮)需要毫秒级响应,用同一个定时器轮询,要么浪费资源,要么漏掉关键事件。
错误四:忽略工程量转换。 现场 AI 信号通常是 4~20mA 或 0~10V 的电信号,PLC 读到的原始值可能是 0~4095(12位ADC)。不做工程量转换直接存库,业务人员完全看不懂。
我最终选择的方向
根据项目经验,我倾向于将信号点位的元数据与采集数据分离存储:
- 元数据表(
signal_point):定义信号类型、方向、工程量范围、单位、业务含义 - 数字量历史表(
signal_digital_history):只存 0/1 的状态变化记录(边沿存储) - 模拟量历史表(
signal_analog_history):存连续采样值,支持按时间段查询
这样的好处是:采集层和业务层解耦,新增点位只需维护元数据,不需要改代码。
三、技术方案
整体架构
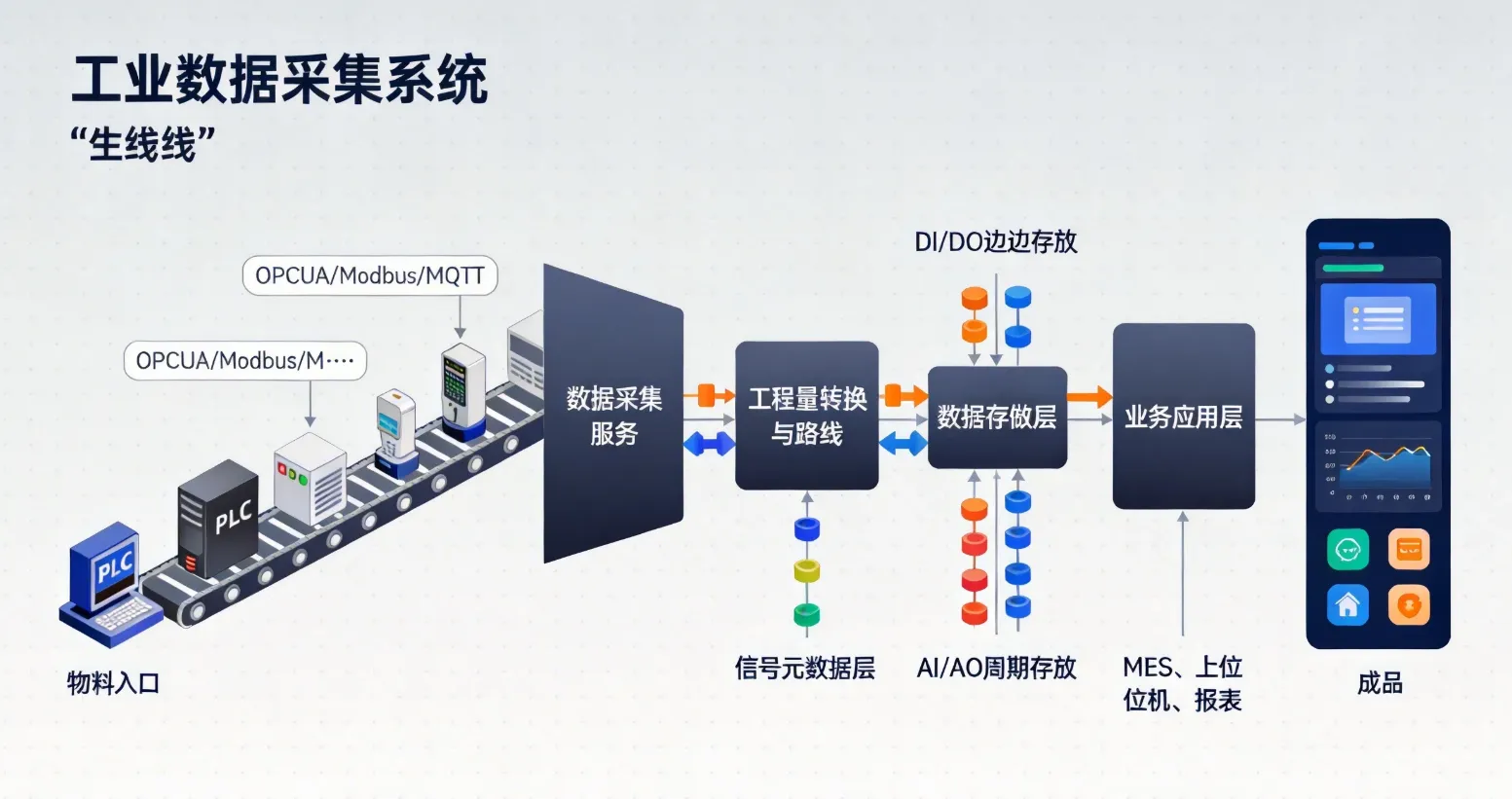
边沿存储的含义是:DI/DO 信号只在状态发生变化时(0→1 或 1→0)写入一条记录,而不是每秒都写。这对于开关量来说极大减少了写入量,同时保留了完整的状态变化历史。
数据库设计
信号点位元数据表 signal_point
sqlCREATE TABLE signal_point (
id BIGINT NOT NULL PRIMARY KEY, -- 点位ID
point_code VARCHAR(64) NOT NULL UNIQUE, -- 点位编码,如 "L01_SPINDLE_CURRENT"
point_name VARCHAR(128) NOT NULL, -- 点位名称
signal_type TINYINT NOT NULL, -- 1=DI 2=DO 3=AI 4=AO
direction TINYINT NOT NULL, -- 1=Input 2=Output
device_id BIGINT NOT NULL, -- 关联设备ID
raw_min DECIMAL(18,4) NULL, -- 原始值下限(AI/AO用)
raw_max DECIMAL(18,4) NULL, -- 原始值上限(AI/AO用)
eng_min DECIMAL(18,4) NULL, -- 工程量下限
eng_max DECIMAL(18,4) NULL, -- 工程量上限
unit VARCHAR(32) NULL, -- 单位,如 "A"、"℃"、"rpm"
business_tag VARCHAR(128) NULL, -- 业务语义标签,如 "主轴电流"
alarm_high DECIMAL(18,4) NULL, -- 高报阈值
alarm_low DECIMAL(18,4) NULL, -- 低报阈值
is_enabled TINYINT NOT NULL DEFAULT 1, -- 是否启用
remark VARCHAR(256) NULL,
created_at DATETIME NOT NULL,
updated_at DATETIME NOT NULL
);
数字量历史表 signal_digital_history(边沿存储)
sqlCREATE TABLE signal_digital_history (
id BIGINT NOT NULL PRIMARY KEY,
point_id BIGINT NOT NULL, -- 关联 signal_point.id
point_code VARCHAR(64) NOT NULL, -- 冗余存储,查询方便
value TINYINT NOT NULL, -- 0 或 1
edge_type TINYINT NOT NULL, -- 1=上升沿(0→1) 2=下降沿(1→0)
occurred_at DATETIME(3) NOT NULL, -- 毫秒精度时间戳
source VARCHAR(32) NULL, -- 数据来源:OPC/Modbus/MQTT
INDEX idx_point_time (point_id, occurred_at)
);
模拟量历史表 signal_analog_history(周期存储)
sqlCREATE TABLE signal_analog_history (
id BIGINT NOT NULL PRIMARY KEY,
point_id BIGINT NOT NULL,
point_code VARCHAR(64) NOT NULL,
raw_value DECIMAL(18,4) NOT NULL, -- PLC原始值
eng_value DECIMAL(18,4) NOT NULL, -- 工程量换算后的值
quality TINYINT NOT NULL DEFAULT 1, -- 数据质量:1=Good 0=Bad
sampled_at DATETIME(3) NOT NULL, -- 采样时间
INDEX idx_point_time (point_id, sampled_at)
);
模拟量历史表数据量增长极快。在实际项目中,建议按月分表,或使用 TimescaleDB / InfluxDB 等时序数据库存储 AI/AO 历史数据,SQL Server 或 MySQL 仅保留近 N 天的热数据。
去年我接手一个化工厂的上位机改造项目,前任开发者留下来的系统跑了五年,SQLite数据库文件有将近12GB。某天夜班,工控机硬盘突发坏道,系统直接挂掉。运维打电话过来问我:备份在哪?
翻遍整台机器,没有。一条备份脚本都没有。
五年的设备运行记录、工艺参数历史、报警日志——全没了。那次事故最终导致工厂停产将近两天,损失不是我能估算的数字。
这件事给我的教训很深:备份不是"有空了再做"的事,是系统上线第一天就必须到位的基础设施。 工业场景尤其如此——设备数据往往不可再生,一旦丢失,没有任何办法补回来。
这篇文章,咱们就把工业SQLite数据库的备份与恢复这件事,从头到尾说清楚。代码全部可以直接跑,不是那种"示意性伪代码"。
🔍 工业备份的特殊挑战
普通Web应用的备份,停服、导出、完事。工业数据库不行。
原因有三个。第一,不能停服。 设备24小时上报数据,你不可能为了备份让PLC停止通信。第二,数据库文件可能很大。 跑了几年的工业数据库,几个GB到几十GB很正常,直接复制文件的时间窗口太长,期间数据库状态可能变化。第三,恢复时间要求苛刻。 工厂等不起,恢复必须快,最好能精确到某个时间点。
这三个约束,决定了工业备份策略必须比普通应用更精细。
SQLite提供了一个官方的热备份API——sqlite3_backup,Python的sqlite3模块直接封装了这个接口,叫做conn.backup()。它的核心优势是在数据库正常读写的同时完成备份,不需要锁表,不影响业务。这是工业场景备份的基础工具。
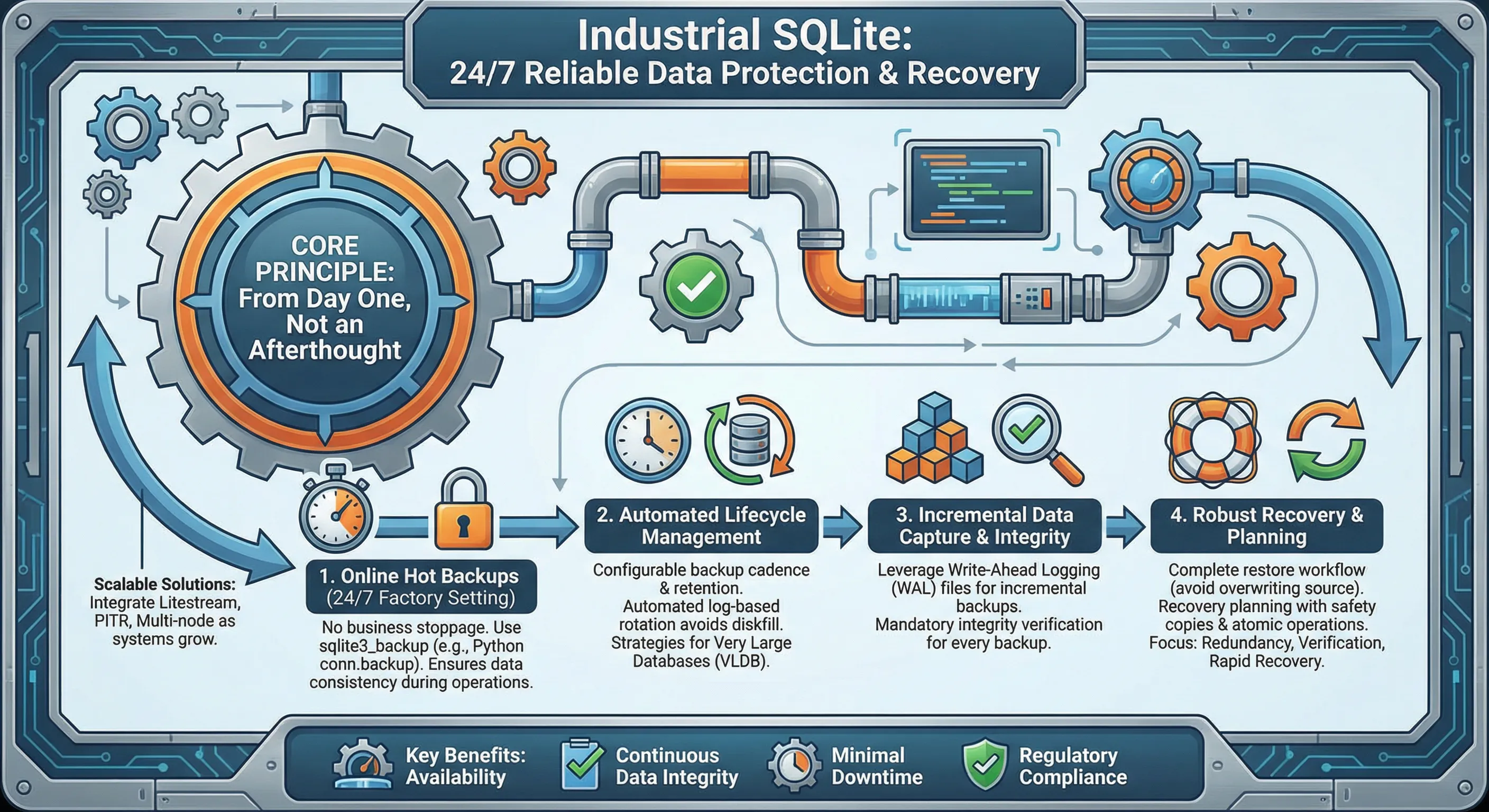
🚀 方案一:在线热备份,业务不停机
先把最基础的热备份封装好:
pythonimport sqlite3
import os
import time
import shutil
from datetime import datetime
from pathlib import Path
class IndustrialBackupManager:
"""
工业数据库备份管理器
核心设计原则:备份过程对业务零干扰
"""
def __init__(self, source_db: str, backup_dir: str):
self.source_db = source_db
self.backup_dir = Path(backup_dir)
self.backup_dir.mkdir(parents=True, exist_ok=True)
def hot_backup(self, pages_per_step: int = 100, sleep_ms: int = 10) -> str:
"""
在线热备份 —— 数据库正常运行时安全复制
pages_per_step: 每步复制的页数,越小对业务影响越低
sleep_ms: 每步之间的休眠毫秒数,让出CPU给业务线程
返回: 备份文件路径
"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
backup_path = self.backup_dir / f"backup_{timestamp}.db"
source_conn = sqlite3.connect(self.source_db)
backup_conn = sqlite3.connect(str(backup_path))
try:
# progress_callback 每步都会被调用,可以在这里记录进度
def progress_callback(status, remaining, total):
if total > 0:
pct = (total - remaining) / total * 100
print(f"\r备份进度: {pct:.1f}% ({total-remaining}/{total} pages)",
end='', flush=True)
source_conn.backup(
backup_conn,
pages=pages_per_step, # 每次复制100页
progress=progress_callback,
sleep=sleep_ms / 1000.0 # 转换为秒
)
print(f"\n热备份完成: {backup_path}")
return str(backup_path)
finally:
source_conn.close()
backup_conn.close()
def verify_backup(self, backup_path: str) -> bool:
"""
备份完整性验证 —— 备份了但没验证,等于没备份
SQLite的integrity_check会检查页校验和、索引一致性等
"""
try:
conn = sqlite3.connect(backup_path)
cursor = conn.cursor()
cursor.execute('PRAGMA integrity_check')
result = cursor.fetchone()
conn.close()
is_ok = result[0] == 'ok'
status = "✅ 完整" if is_ok else f"❌ 损坏: {result[0]}"
print(f"备份验证 [{Path(backup_path).name}]: {status}")
return is_ok
except Exception as e:
print(f"❌ 验证失败: {e}")
return False
pages_per_step这个参数值得多说一句。SQLite数据库由固定大小的页(默认4KB)组成,backup()每次复制pages页后会暂停sleep秒,让业务线程有机会继续写入。值设得越小,备份对业务的影响越低,但备份总时间也越长。工业场景里,我一般设100页 + 10ms休眠,在一台普通工控机上备份1GB数据库大约需要3~4分钟,业务完全无感知。