
在Python面向对象编程中,你是否遇到过这样的困惑:为什么有些类可以直接用len()函数,有些却不行?为什么字符串可以用+连接,而自定义的类却报错?其实,这背后隐藏着Python的"魔法方法"(Special Methods),也叫双下划线方法(Dunder Methods)。
掌握魔法方法,就像给你的类装上了"超能力",让它们能够与Python的内置函数、操作符无缝配合。本文将带你深入了解Python魔法方法的实战应用,从基础概念到高级技巧,助你写出更加pythonic的代码。无论你是Python初学者还是有一定经验的开发者,都能在这里找到实用的编程技巧。
🤔 什么是魔法方法?为什么需要它们?
问题分析
在日常的Python开发中,我们经常会遇到这样的场景:
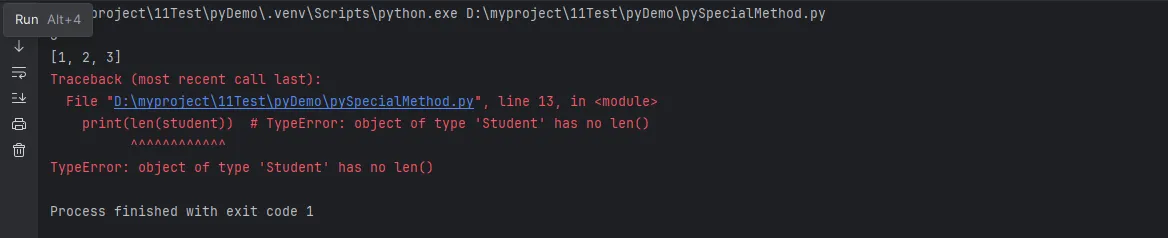
Python# 内置类型可以这样用
numbers = [1, 2, 3]
print(len(numbers)) # 3
print(str(numbers)) # '[1, 2, 3]'
# 但自定义类却不行
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
student = Student("张三", 20)
print(len(student))
在Python开发中,你是否遇到过这样的困扰:团队成员随意修改类的内部属性,导致程序出现莫名其妙的bug?或者在维护老代码时,不敢轻易修改某个属性,生怕影响到其他模块?
这些问题的根源在于缺乏良好的封装设计。封装不仅是面向对象编程的三大特性之一,更是构建健壮、可维护Python应用的基石。本文将从实战角度,带你深入理解Python中的封装机制与私有属性的最佳实践。
无论你是正在开发桌面应用的上位机开发者,还是构建Web服务的后端工程师,掌握封装技巧都能让你的代码质量产生质的飞跃。
🔍 问题分析:封装解决了什么痛点?
💥 常见的代码灾难现场
让我先展示一个典型的"问题代码":
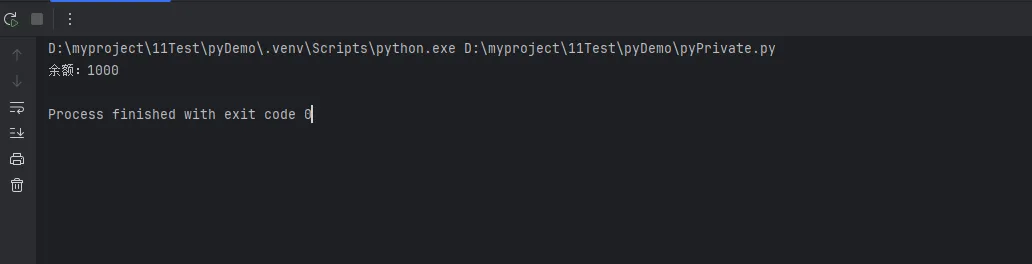
Pythonclass BankAccount:
def __init__(self, account_number, balance):
self.account_number = account_number
self.balance = balance
def deposit(self, amount):
self.balance += amount
def withdraw(self, amount):
if self.balance >= amount:
self.balance -= amount
return True
return False
# 使用场景
account = BankAccount("123456", 1000)
print(f"余额:{account.balance}") # 1000
# 灾难开始...
account.balance = -5000 # 直接修改,余额变成负数!
account.account_number = "hacker" # 账号被篡改!
 问题显而易见:
问题显而易见:
在Python开发中,你是否遇到过这样的困扰:同样的方法名,却需要在不同的类中写出不同的实现?或者在处理不同类型的对象时,总是需要写大量的if-else判断?这些问题的根源在于没有充分理解和运用Python的多态特性。
多态(Polymorphism)是面向对象编程的三大特性之一,它能让我们的代码变得更加灵活、可扩展、易维护。今天这篇文章将通过实战案例,带你深入理解Python多态的核心概念和应用技巧,让你的代码从此告别冗余,拥抱优雅。
🔍 什么是多态?为什么需要它?
📖 多态的定义
多态(Polymorphism)源自希腊语,意思是"多种形态"。在编程中,多态指的是同一个接口可以有多种不同的实现方式,调用者无需关心具体的实现细节,只需要知道接口的规范即可。
简单来说:同一个方法名,不同的对象调用时产生不同的行为。
🤔 为什么需要多态?
想象一下这个场景:你在开发一个图形绘制程序,需要处理圆形、矩形、三角形等不同的图形。如果没有多态:
Python# ❌ 没有多态的代码 - 难以维护
def draw_shape(shape):
if shape.type == "circle":
# 绘制圆形的复杂逻辑
print(f"绘制圆形,半径:{shape.radius}")
elif shape.type == "rectangle":
# 绘制矩形的复杂逻辑
print(f"绘制矩形,宽:{shape.width},高:{shape.height}")
elif shape.type == "triangle":
# 绘制三角形的复杂逻辑
print(f"绘制三角形,边长:{shape.sides}")
# 每增加一种新图形,都要修改这个函数
这种写法的问题显而易见:
- 代码冗余:大量的if-else判断
- 难以扩展:每新增一种图形,都要修改现有代码
- 容易出错:修改时可能影响其他图形的逻辑
- 违反开闭原则:对扩展不开放,对修改不封闭
在SQL Server中,文件组和数据文件是组织和存储数据库数据的重要组成部分。正确的文件组和数据文件的使用策略可以提高数据库的性能和可维护性。本文将详细介绍文件组和数据文件的概念,并提供一些使用策略的建议。
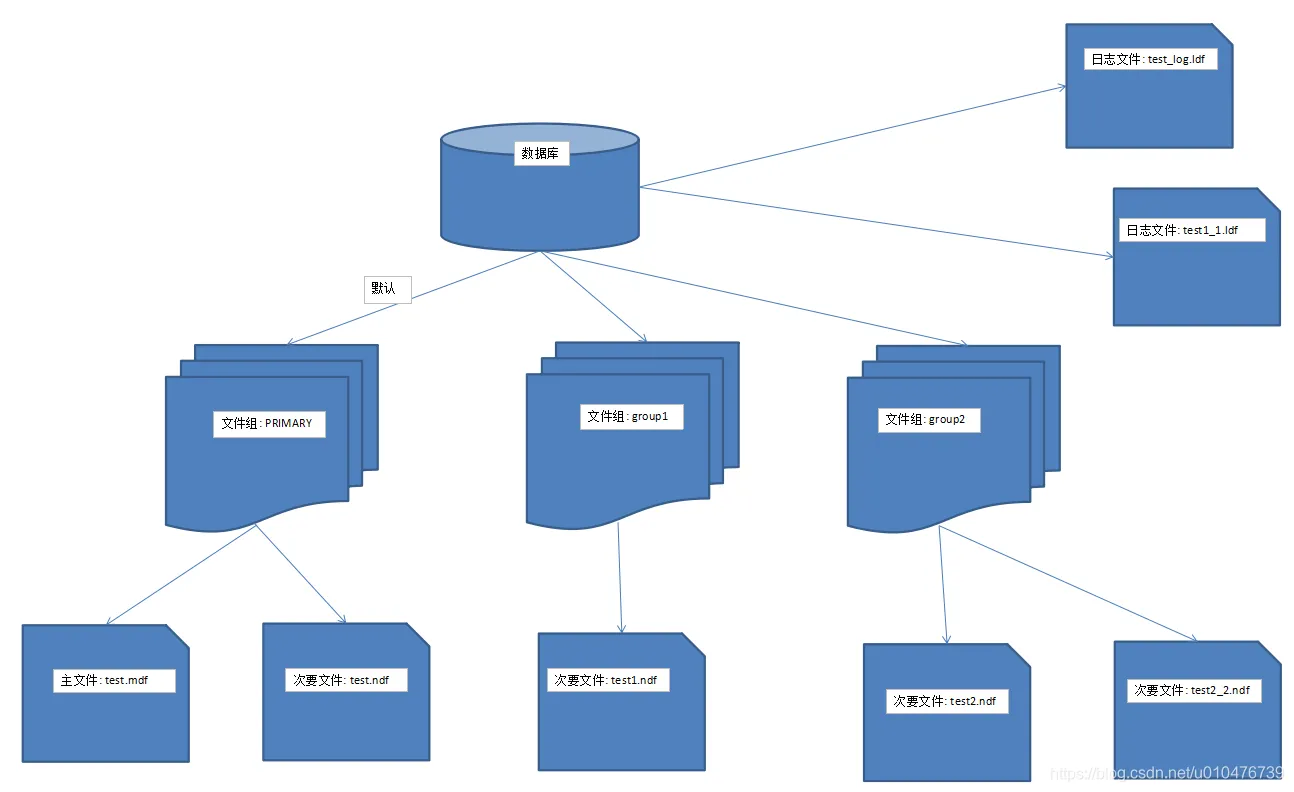
1. 文件组的概念
文件组是一组数据文件的逻辑容器,用于存储数据库中的表、索引和其他对象。每个数据库可以包含一个或多个文件组,每个文件组可以包含一个或多个数据文件。文件组可以位于不同的物理存储设备上,从而实现数据的分布和并行访问。
2. 数据文件的概念
数据文件是文件组中实际存储数据的物理文件。每个数据文件都有固定的大小,并且可以自动增长以适应数据的增加。数据文件的大小和增长策略对于数据库的性能和可维护性至关重要。
在 SQL Server 中,数据库由两种主要类型的文件组成:数据文件和事务日志文件。数据文件包含数据库的实际数据和对象,如表、视图、存储过程等。而事务日志文件记录所有对数据库所做的更改,以便在系统故障时恢复数据。合理配置这两种文件对于数据库的性能和可靠性至关重要。
数据文件(MDF 和 NDF)
数据文件是数据库的主要存储组件,包含了所有数据和数据库对象。主数据文件(MDF)是数据库的主文件,而次要数据文件(NDF)是可选的,用于存储额外的数据。
数据文件配置的最佳实践
- 文件位置:将数据文件放置在快速、可靠的存储系统上,最好是专用的SSD。
- 文件大小:预先分配一个足够大的文件大小,以避免频繁自动增长。
- 自动增长:设置一个合理的自动增长值,以避免因为频繁的小幅度增长导致性能问题。
- 文件分组:使用文件分组可以将数据分布到多个文件中,这有助于提高性能。