摘要
二元情绪分类器是一种能够自动分类文本或数据情感的机器学习模型。它的目的是将文本数据自动分类为正面或负面情绪。通常,二元情绪分类器被用于社交媒体上的评论、产品评论或用户反馈分析。这种分析可以帮助企业和组织更好地了解用户对其产品、服务或品牌的态度和情绪。
二元情绪分类器的训练过程是利用已经标记好的数据,训练模型从中学习如何从文本中提取情感特征,并将其与相应的情绪类别相关联。一旦模型训练完成,它可以自动预测新的文本数据的情感类别。
使用二元情绪分类器可以大量自动化地进行文本数据的情感分析。这种分析可以帮助企业和组织更好地理解用户的情感和反馈,以便作出相应的决策和改进。
正文
常见应用场景
- 社交媒体监控:企业和品牌可以使用二元情绪分类器来监控社交媒体上的公众情绪,了解客户对产品或服务的看法,以及市场对新发布或事件的反应。
- 客户服务:自动化客户服务工具(如聊天机器人)可以利用情绪分类器来识别客户的情绪状态,并据此调整对话策略或将复杂的情绪问题转交给人工服务人员。
- 产品评论分析:通过分析在线产品评论的情绪,公司可以获得关于哪些功能受欢迎以及哪些可能需要改进的见解。
- 市场调研:市场研究人员可以使用情绪分类器来分析调查反馈、消费者讨论组或论坛的内容,以了解消费者的情绪倾向和品牌形象。
- 股市分析:金融分析师可能会使用情绪分类器来评估新闻文章、社交媒体帖子或分析师报告中的情绪,作为预测股市趋势的一个因素。
- 政治舆情分析:在政治领域,情绪分类器可以帮助分析公众对政策、政治人物或选举的情绪反应。
- 危机管理:在危机情况下,组织可以使用情绪分类器来监控公众的情绪反应,以便更有效地管理通信和缓解策略。
- 健康护理:在心理健康领域,情绪分类器可以帮助识别患者的情绪状态,为临床决策提供支持。
- 内容过滤:在线平台可以使用情绪分类器来识别和过滤掉具有负面情绪的有害内容,如网络欺凌或仇恨言论。
- 娱乐分析:影视和音乐产业可以使用情绪分类器来分析观众对特定作品的情绪反应,从而指导营销策略或未来作品的创作。
构建有效的二元情绪分类器通常涉及自然语言处理(NLP)和机器学习技术,例如情感词典、支持向量机(SVM)、深度学习等。这些分类器的性能可能会受到训练数据的质量、文本数据的复杂性和上下文的影响。因此,为了提高准确性,可能需要对分类器进行定制和细化,以适应特定的应用场景和领域。
摘要
ML.NET是一个开源的机器学习框架,由微软开发和维护。它是专门为.NET开发者设计的,可以在.NET平台上轻松地集成和使用机器学习模型。
ML.NET提供了一组易于使用的API和工具,使开发者能够在.NET应用程序中使用机器学习技术。它支持各种常见的机器学习任务,包括分类、回归、聚类和推荐等。开发者可以使用ML.NET来训练和评估机器学习模型,然后将其集成到他们的应用程序中,以进行预测和推断。
正文
ML.NET具有以下特点和优势:
- 简单易用:ML.NET提供了简单易用的API和工具,使开发者能够快速上手并使用机器学习技术,无需深入了解复杂的算法和数学原理。
- 跨平台支持:ML.NET可以在Windows、Linux和macOS等平台上运行,使开发者能够在不同的操作系统上开发和部署机器学习应用程序。
- 集成性:ML.NET可以与.NET生态系统中的其他组件和工具集成,如ASP.NET、Azure、SQL Server等,使开发者能够将机器学习技术无缝地集成到他们的应用程序和解决方案中。
- 可扩展性:ML.NET支持使用自定义的机器学习模型和算法,开发者可以根据自己的需求和场景进行扩展和定制。
- 性能优化:ML.NET针对.NET平台进行了性能优化,可以高效地处理大规模数据和复杂的机器学习任务。
第一个示例
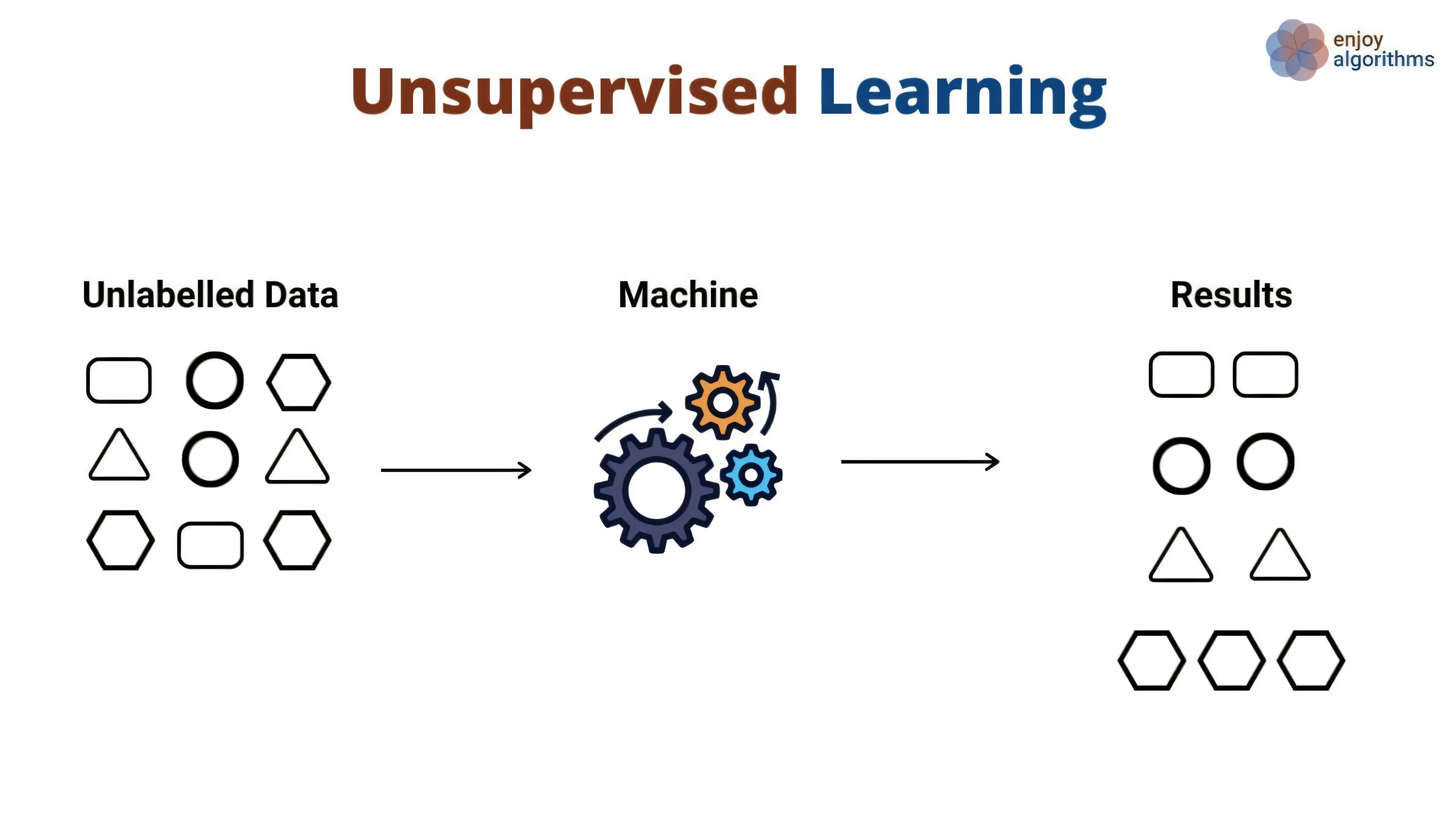
非监督学习(Unsupervised Learning)是机器学习中的一种重要范式,它的目标是从未标记(无监督)的数据集中发现数据的内在结构和规律。与监督学习不同,非监督学习不需要预先标记的训练数据,通过挖掘数据本身的分布和特征来进行模式识别、聚类、降维等任务。
主要应用场景
-
聚类分析(Clustering)
非监督学习常被用于聚类分析任务,根据数据相似性将样本自动划分到不同的聚合簇中。例如,对市场上的消费者进行细分,从而在精准营销中针对不同人群采取不同策略。
-
异常检测(Anomaly Detection)
非监督学习可用于检测出与大部分样本差异显著的“异常点”。例如,金融交易中的欺诈交易检测,网络中的入侵检测,传感器数据中的故障检测等。
-
降维和可视化(Dimensionality Reduction and Visualization)
当数据的特征特别高维且较难可视化时,非监督学习算法(如PCA)可以将高维数据投影到更低维的空间,以便进行可视化或后续分析。
-
特征学习(Feature Learning)
通过非监督学习的方法对数据进行学习,从而得到有意义的特征表示。典型的自动编码器(Autoencoder)就能学习紧凑的特征向量表示,为后续的分类或回归任务提供支持。
-
文档和文本挖掘
在自然语言处理和信息检索领域,通过主题模型(如LDA)可以从海量文本中自动挖掘主题,从而帮助理解文档的主要内容或趋势。
在众多机器学习方法中,监督学习(Supervised Learning)是一种应用最为广泛、技术最为成熟的分支。它通过给定的带标签(label)数据,让模型学会从输入(feature)到输出(label)的映射关系,并在此基础上对未知数据进行预测。下面将对监督学习的基本概念、常用算法、训练过程以及评估指标等方面进行详细说明。
监督学习的基本概念
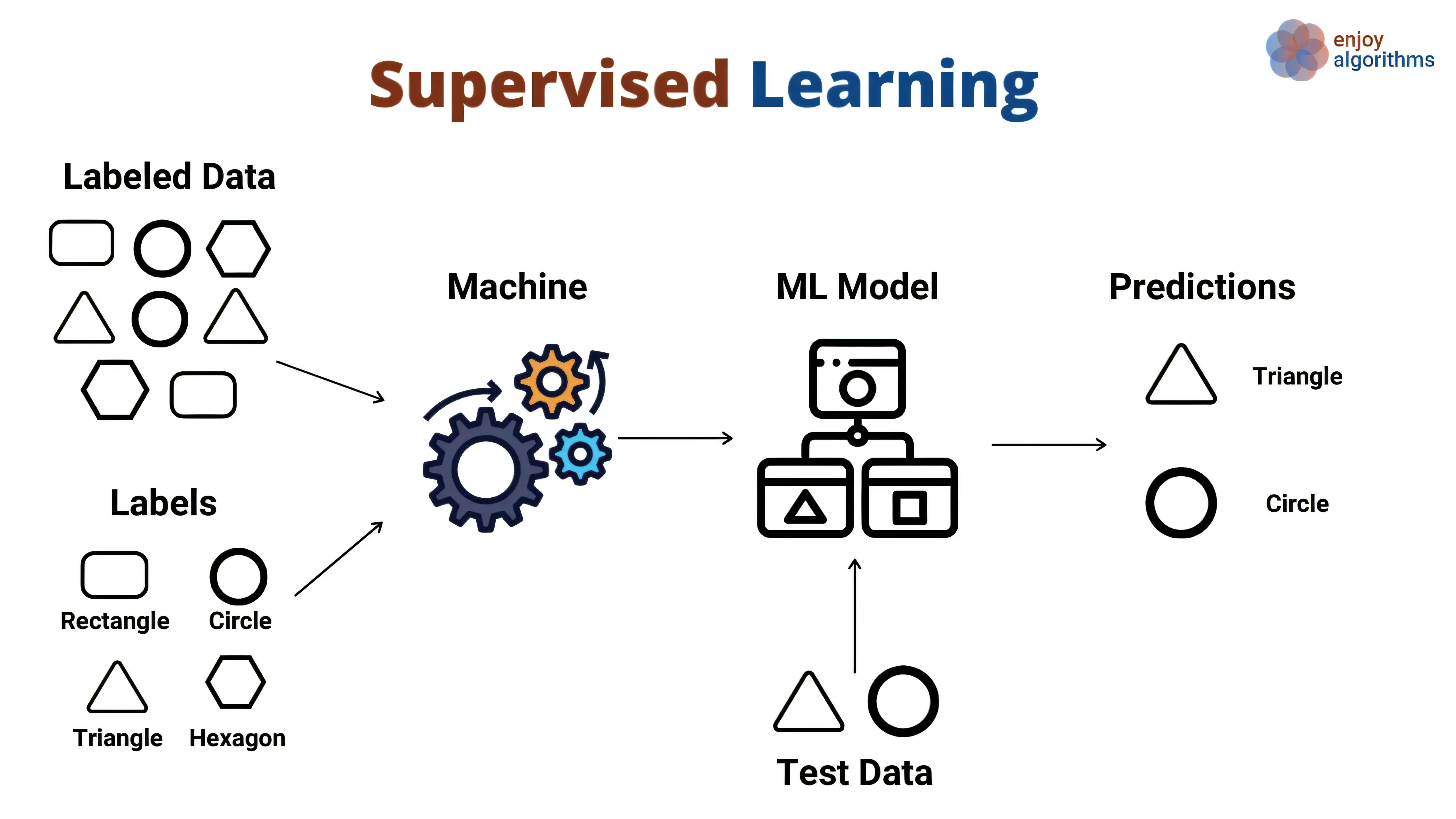
监督学习的核心在于“输入特征”与“目标输出”之间的函数映射。模型通过学习已有数据集(包含已知的输入和对应的正确输出),不断迭代更新其内部参数(如神经网络的权重,线性回归的系数等),从而使模型能够在未见过的新数据上也做出尽可能准确的预测。
中文注释:
- 输入特征(features):样本所具有的可测量属性或维度。
- 目标输出(label):在模型训练时作为“正确答案”的标签信息,用于指导模型学习。
根据预测任务的不同,监督学习一般分为以下两类:
- 回归问题(Regression):输出结果为连续值,例如房价预测、温度预测等。
- 分类问题(Classification):输出结果为离散类别,例如垃圾邮件识别、图像分类等。
在Python面向对象编程中,你是否遇到过这样的困扰:想要为类的方法添加日志记录、性能监控或权限验证,却不想修改原有的业务逻辑代码?想要让代码更加简洁优雅,但又担心破坏现有的类结构?
今天我们就来深入探讨装饰器在面向对象编程中的应用,这个被称为Python"语法糖"的神奇功能。通过本文,你将掌握如何在类和方法中巧妙运用装饰器,让你的Python开发更加高效,代码更加优雅。无论你是在做上位机开发还是其他Python项目,装饰器都将成为你编程技巧中的重要利器。
🔍 问题分析:为什么需要装饰器?
💻 传统方式的痛点
在面向对象编程中,我们经常需要为类的方法添加额外功能,比如:
Pythonclass DataProcessor:
def process_data(self, data):
# 记录开始时间
import time
start_time = time.time()
print(f"开始处理数据: {time.strftime('%Y-%m-%d %H:%M:%S')}")
# 业务逻辑
result = [x * 2 for x in data]
# 记录结束时间
end_time = time.time()
print(f"处理完成,耗时: {end_time - start_time:.2f}秒")
return result
这种方式存在明显的问题:
- 代码冗余:每个方法都需要重复写日志代码
- 职责混乱:业务逻辑和辅助功能混在一起
- 维护困难:修改日志格式需要改动多个地方
🎯 装饰器的优势
装饰器能够完美解决上述问题:
- 关注点分离:业务逻辑和辅助功能完全分离
- 代码复用:一个装饰器可以应用到多个方法
- 动态增强:不修改原有代码就能添加新功能
💡 解决方案:装饰器的工作原理
🔧 基础装饰器概念
装饰器本质上是一个高阶函数,它接受一个函数作为参数,返回一个增强后的函数:
Pythondef my_decorator(func):
def wrapper(*args, **kwargs):
# 执行前的操作
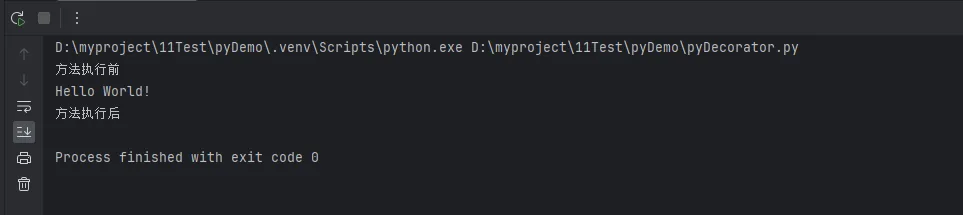
print("方法执行前")
result = func(*args, **kwargs)
# 执行后的操作
print("方法执行后")
return result
return wrapper
# 使用装饰器
@my_decorator
def say_hello():
print("Hello World!")
say_hello()