
🎯 痛点开场:工业界面的"致命三秒"
去年帮一家智能制造企业做技术咨询时,遇到个让人头疼的问题:他们的生产监控系统每隔3-5秒就会卡顿一次,操作员盯着屏幕干着急。50多个传感器数据每秒刷新10次,界面直接"罢工",甚至出现过因为界面卡死错过报警信息,导致一批产品报废的严重事故。
这其实是很多工业软件开发者的噩梦:传统 WinForms 思维写 WPF,数据一多就完蛋。咱们都知道工业场景不比普通应用,温度、压力、转速这些参数必须毫秒级响应,界面稍有延迟就可能造成安全隐患。
读完这篇文章,你将掌握:
- 工业级实时数据显示的三大核心机制
- 从30%CPU占用降到5%的实战优化方案
- 可直接复用的高性能数据绑定模板
- 避开90%新手会踩的UI线程陷阱
🔍 问题深度剖析:为什么你的界面会"卡成PPT"
根源一:UI线程被"绑架"了
很多开发者习惯这样写数据更新:
csharp// ❌ 错误示范:直接在数据接收线程更新UI
private void OnDataReceived(SensorData data)
{
txtTemperature.Text = data.Temperature.ToString();
txtPressure.Text = data.Pressure.ToString();
// 50个参数就要写50行...
}
这玩意儿看起来简单,实则每次更新都在强奸UI线程。工业场景下,数据采集线程每秒可能触发几百次回调,UI线程根本喘不过气。我在测试环境做过对比,这种写法CPU占用能飙到35%,而且界面响应延迟达到200-500ms。
根源二:数据绑定用错了姿势
另一种常见错误是滥用 INotifyPropertyChanged:
csharp// ⚠️ 性能杀手:每个属性变化都触发UI刷新
public class SensorViewModel : INotifyPropertyChanged
{
private double _temperature;
public double Temperature
{
get => _temperature;
set
{
_temperature = value;
OnPropertyChanged(nameof(Temperature)); // 每秒触发10次
}
}
// 50个属性 × 10次/秒 = 500次UI刷新/秒
}
这种写法在参数少的时候没问题,但工业界面动辄几十上百个参数,属性变化事件会像雪崩一样冲垮渲染管线。
根源三:忽视了WPF的渲染机制
WPF的布局系统分为 Measure → Arrange → Render 三个阶段。每次属性变化都会触发这套流程,如果你的界面嵌套了复杂的Grid、StackPanel,再加上各种Style和Template,单次渲染耗时能达到15-30ms。50个参数同时更新?恭喜你喜提界面冻结。
💡 核心要点提炼:工业级UI的生存法则
在深入解决方案之前,咱们先理清几个关键原则:
🎯 原则1:数据采集与UI更新必须解耦
永远不要在数据线程直接操作UI元素。这是铁律。工业软件的数据采集通常跑在独立线程(甚至独立进程),必须通过调度器(Dispatcher)或消息队列与UI通信。
🎯 原则2:批量更新优于频繁触发
与其每个参数变化都通知UI,不如攒一批数据统一提交。比如100ms收集一次数据快照,然后一次性更新界面,这样能把刷新频率从每秒500次降到10次。
🎯 原则3:虚拟化才是大数据量的解药
如果你需要展示的参数超过100个,老老实实用 VirtualizingStackPanel。只渲染可见区域,其他的让WPF自己管理,CPU占用能降低60%-80%。
🎯 原则4:绑定路径越短越好
Binding Path 每多一层,性能就打一次折扣。尽量扁平化ViewModel结构,避免 {Binding Parent.Child.GrandChild.Value} 这种套娃写法。
说真的,第一次听到有人把 MVVM 和 Tkinter 放在一起聊,我的第一反应是——这俩能搭吗?
Tkinter 嘛,老派、朴素,Python 自带的 GUI 库,很多人对它的印象还停留在"能用就行"的阶段。MVVM 呢,则是 WPF、Vue、SwiftUI 这些现代框架里的核心设计思想,强调数据绑定、响应式更新、关注点分离。把这两个东西硬拼在一起,听起来有点像用老式煤气灶做分子料理——不是不行,但得费点心思。
但我在一个实际项目里这么干了。而且干完之后,代码的可维护性提升了不少,后来加功能的时候明显感觉轻松了很多。所以今天就来聊聊这件事。
🤔 先说说为什么要这么做
先把问题摆出来。你有没有写过这样的 Tkinter 代码:
pythondef on_button_click():
name = entry_name.get()
if not name:
label_error.config(text="姓名不能为空")
return
result = do_some_business_logic(name)
label_result.config(text=result)
listbox.insert(END, result)
btn_submit.config(state=DISABLED)
这段代码本身没什么大毛病。但它把三件事混在了一起:UI 状态读取、业务逻辑处理、UI 状态更新。一个函数,干了三份活。
项目小的时候无所谓。等到界面有二三十个控件、业务逻辑稍微复杂一点,这种写法就开始"还债"了——改一个需求,你得在一堆回调函数里翻来翻去,生怕改了这里漏了那里。测试?基本没法单独测业务逻辑,因为它和 UI 耦合死了。
MVVM 解决的正是这个问题。
🧱 MVVM 是什么,别背定义
Model-View-ViewModel,三层结构。但别去背那些教科书式的定义,用大白话说就是:
- Model:你的数据和业务规则,跟界面没有任何关系
- ViewModel:中间人,持有界面需要的数据,处理用户操作,通知界面更新
- View:就是界面,只管显示和接收输入,不做任何判断
三者之间的关系是单向依赖的:View 依赖 ViewModel,ViewModel 依赖 Model,Model 不认识任何人。
在 WPF 或者 Vue 里,View 和 ViewModel 之间有框架级别的数据绑定机制,变量一改,界面自动刷新。Tkinter 没有这个机制——所以咱们得自己造一个轻量级的"绑定层"。
🔧 核心机制:Observable 属性
整个方案的基础,是一个能"被观察"的属性类。思路很简单:当属性值变化时,主动通知所有订阅了这个变化的回调函数。
pythonclass Observable:
"""可观察属性,值变化时自动触发回调"""
def __init__(self, value=None):
self._value = value
self._callbacks = []
@property
def value(self):
return self._value
@value.setter
def value(self, new_val):
if new_val != self._value:
self._value = new_val
self._notify()
def bind(self, callback):
"""订阅变化事件"""
self._callbacks.append(callback)
def _notify(self):
for cb in self._callbacks:
cb(self._value)
就这么二十几行。但有了它,后面的一切都能串起来。
🤔 你真的用对 Lambda 了吗?
在日常 C# 开发中,Lambda 表达式几乎是使用频率最高的语法特性之一。list.Where(x => x.Age > 18)、Task.Run(() => DoWork())、button.Click += (s, e) => Handle()——这些写法随手就来,顺畅得像呼吸一样自然。
但正因为太顺手,很多开发者从来没有停下来想过:Lambda 背后编译器到底做了什么?闭包捕获变量的时机是什么?匿名方法和 Lambda 有什么本质区别? 这些问题在 Code Review 里很少被追问,但在生产环境里,它们以内存泄漏、逻辑错误、性能劣化的形式悄悄埋下隐患。
我在多个中大型项目中见过这样的场景:一段看似简洁的 Lambda 循环,因为闭包变量捕获时机的误解,导致所有回调执行时拿到的是同一个"最终值",排查了半天才定位到根因。
读完本文,你将掌握:
- Lambda 与匿名方法的编译器处理机制
- 闭包的变量捕获原理与经典陷阱规避
- 3 个渐进式实战方案,覆盖性能优化与架构设计
🔍 问题深度剖析:Lambda 不只是"简化写法"
匿名方法是 Lambda 的前身,但不完全等价
C# 2.0 引入了匿名方法(Anonymous Method),C# 3.0 引入了 Lambda 表达式。很多人认为 Lambda 只是匿名方法的语法糖,这个说法大体正确,但存在一个关键差异。
csharp// C# 2.0 匿名方法写法
Func<int, bool> isEven_old = delegate(int x) { return x % 2 == 0; };
// C# 3.0 Lambda 表达式写法
Func<int, bool> isEven_new = x => x % 2 == 0;
// 两者编译后几乎等价,但匿名方法有一个独特能力:
// 可以忽略参数列表(Lambda 不行)
Action<int, string> ignore = delegate { Console.WriteLine("我不在乎参数"); };
// 等价于:(int _, string _) => Console.WriteLine(...)
// Lambda 必须声明参数,即使不用
这个细节在事件处理中很实用——当你只想订阅事件但不关心参数时,delegate { } 比 (s, e) => { } 更简洁,语义也更明确。
编译器对 Lambda 做了什么?
这才是理解一切的基础。Lambda 表达式在编译时会被转换成以下两种形式之一,取决于它是否捕获了外部变量:
情况一:无捕获变量 → 静态方法
csharpvar numbers = new List<int> { 1, 2, 3, 4, 5 };
// 这个 Lambda 没有捕获任何外部变量
var evens = numbers.Where(x => x % 2 == 0);
编译器会将其优化为一个静态方法,甚至缓存为静态字段,整个程序生命周期只创建一次委托实例。性能最优,无额外内存分配。
情况二:有捕获变量 → 编译器生成闭包类
csharpint threshold = 10; // 外部变量
// 这个 Lambda 捕获了 threshold
var filtered = numbers.Where(x => x > threshold);
编译器会生成一个隐藏的闭包类(编译器命名类似 <>c__DisplayClass0_0),大致等价于:
csharp// 编译器自动生成的闭包类(伪代码)
private sealed class DisplayClass0_0
{
public int threshold; // 捕获的变量变成字段
internal bool FilterMethod(int x)
{
return x > this.threshold; // 通过字段访问
}
}
// 原代码等价于:
var closure = new DisplayClass0_0();
closure.threshold = threshold;
var filtered = numbers.Where(closure.FilterMethod);
关键认知:捕获的是变量本身(引用),不是变量的值的副本。这一点是所有闭包陷阱的根源。
上周有个做自动化的朋友找我抱怨:他们厂里的上位机软件,界面丑得像 2003 年的网吧管理系统,逻辑全堆在一个 Form 里,动不动就假死。他问我,C# 能不能做出像样的 SCADA 界面?我说,不仅能,还能做得很优雅。这篇文章,就把我的实战思路完整拆给你看。
🏭 先搞清楚,SCADA 到底要解决什么问题
SCADA(数据采集与监视控制系统)这个词听起来很唬人,但本质上,它干的事情就三件:采数据、看数据、管设备。
工业现场的开发者最头疼的,不是算法,是结构。你见过那种把所有逻辑全塞进 Form1.cs 的上位机代码吗?定时器回调里直接操 UI,报警判断和趋势绘图混在一起,改一个需求,整个文件都得翻。这玩意儿,维护起来真的是噩梦。
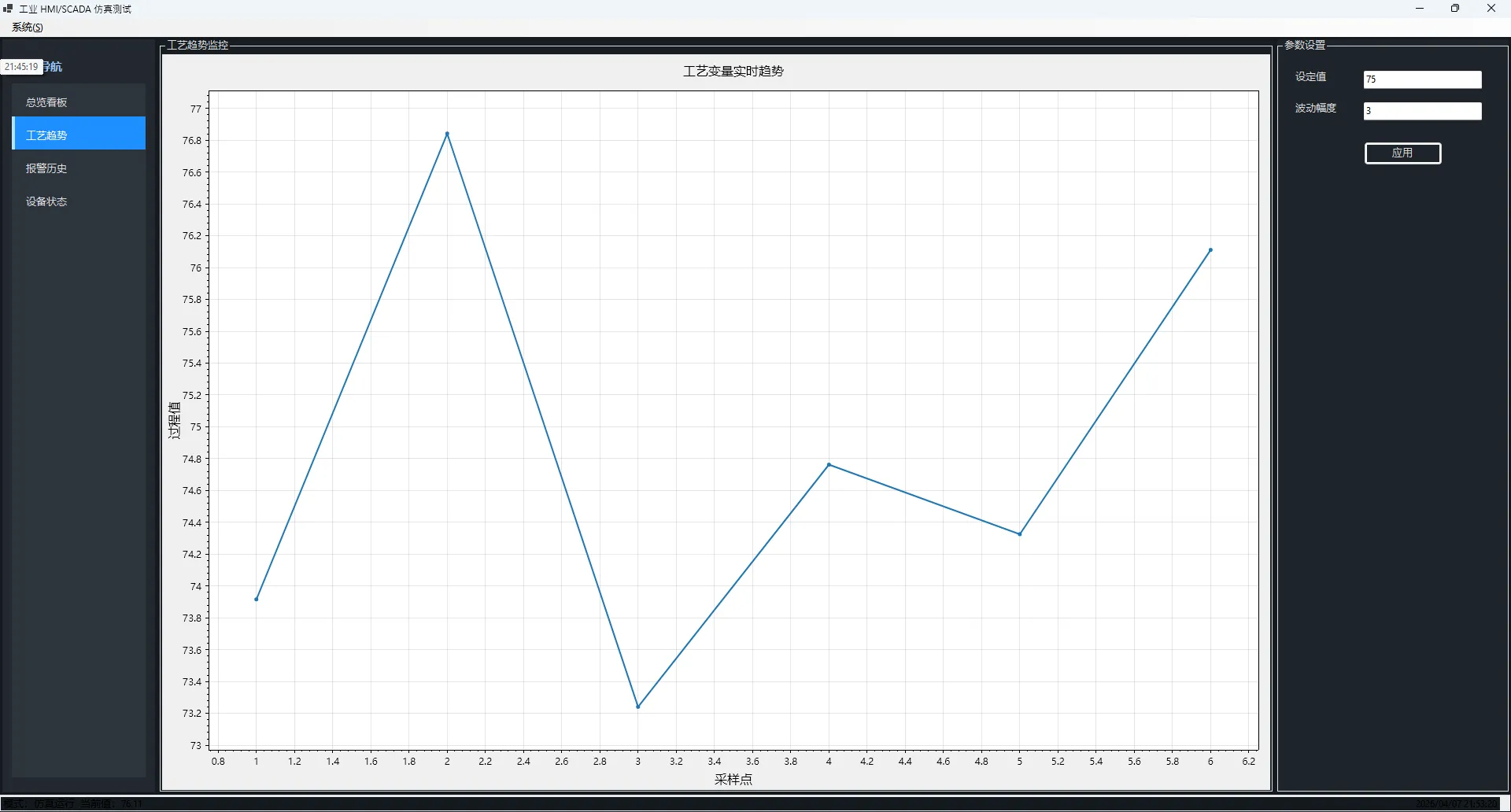
咱们今天要做的这个 Demo,麻雀虽小,五脏俱全——实时趋势、报警历史、设备状态、参数配置,四个模块,一套导航,外加一个仿真引擎驱动数据。
👨💻 看一下样式
🧱 架构先行:别急着写代码
很多人上来就拖控件、写事件,结果代码越写越乱。工业软件有个特点——模块多、状态复杂、需要长期维护。所以在动手之前,先把结构想清楚。
这个项目的核心思路是:单一 Form + 动态模块切换。
不是每个功能一个 Form,也不是 UserControl 堆叠,而是用一个 GroupBox 作为内容区,根据导航选择动态换入不同的控件。听起来简单,但细节里藏着不少门道。
布局上,用 TableLayoutPanel 三列分割:左侧导航、中间内容区、右侧参数面板。右侧面板只在"工艺趋势"模块下可见,其余模块直接把列宽收为 0,视觉上干净利落。
csharpprivate void SetRightPanelVisible(bool visible)
{
pnlRight.Visible = visible;
// 不是 Hide,而是直接把列宽归零——这样布局不会留白
tlpRoot.ColumnStyles[2].Width = visible ? RightPanelWidth : 0F;
}
这个小细节很多人会忽略。直接 Hide 控件,TableLayoutPanel 那一列还是会占位,界面会出现一块莫名其妙的空白。
生产环境某次 AI 调用莫名超时,排查了两小时,最终发现是 Temperature 参数配置异常导致响应时间暴增 300%。如果当时有完善的日志监控体系,这个问题五分钟就能定位。
在构建 Semantic Kernel 应用时,日志与监控往往是最容易被忽视的环节。代码跑通了、接口通了,然后就直接上线——这种操作在小项目里或许无伤大雅,但在生产环境中,一旦出现 AI 调用失败、Token 超支、响应延迟飙升等问题,没有监控就等于盲开飞机。
读完本文,你将掌握:
- ILogger 与 Semantic Kernel 的深度集成方式
- Serilog 结构化日志的实战配置
- Application Insights 遥测接入
- 性能分析工具的选用与使用技巧
- 一套可直接复用的完整日志监控系统模板
1️⃣ 问题深度剖析:没有监控的 AI 应用有多危险
🚨 三个典型痛点场景
痛点一:AI 调用失败后无迹可查
很多项目的错误处理长这样:
csharp// ❌ 典型的"吞掉异常"写法
try
{
var result = await kernel.InvokePromptAsync(prompt);
return result.ToString();
}
catch (Exception ex)
{
return "服务暂时不可用"; // 问题被掩盖,运维完全不知道
}
这种写法导致的后果是:用户反馈"AI 不好用",运维查不到任何错误信息,开发只能干瞪眼。
痛点二:Token 消耗失控
Semantic Kernel 每次调用都会消耗 Token,如果没有监控,以下情况很容易发生:
- ChatHistory 无限增长,单次请求 Token 超 8000
- 某个插件被频繁触发,一天消耗正常量的 10 倍
- 生产环境 Temperature=0.9(本该是开发配置),导致回复质量下降
痛点三:性能劣化无法感知
没有追踪时,你根本不知道:响应从 800ms 变成 3000ms 是从哪天开始的?是模型接口变慢了,还是某个插件计算耗时暴增?
2️⃣ 核心要点提炼:日志监控的底层逻辑
📐 分层监控模型
一个完整的 Semantic Kernel 监控体系,需要覆盖三层:
| 层级 | 监控内容 | 工具选型 |
|---|---|---|
| 应用层 | 业务逻辑、用户请求、对话历史 | ILogger + Serilog |
| 框架层 | SK 内核事件、函数调用、插件触发 | SK 内置事件钩子 |
| 基础设施层 | HTTP 请求、延迟、Token 用量 | Application Insights |
🔑 关键设计原则
- 结构化优于文本:
logger.LogInformation("Token: {TokenCount}", count)远比logger.LogInformation($"Token: {count}")好查询 - 上下文随调用链传递:每次 AI 调用应携带 TraceId,便于端到端追踪
- 性能数据必须量化:记录耗时、Token 数、重试次数,不能只记"成功/失败"
3️⃣ 解决方案设计
🛠️ 方案一:ILogger 基础集成(适合快速起步)
这是最轻量的方案,适合中小项目快速接入监控能力。
第一步:配置日志级别
json// appsettings.json
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.SemanticKernel": "Debug",
"AppAiAgent": "Debug"
}
}
}
💡 将
Microsoft.SemanticKernel设为Debug,SK 框架会自动输出函数调用、模型请求等详细信息。
第二步:封装带监控的 AI 服务
csharpusing Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Diagnostics;
public class MonitoredAIService
{
private readonly Kernel _kernel;
private readonly ILogger<MonitoredAIService> _logger;
public MonitoredAIService(Kernel kernel, ILogger<MonitoredAIService> logger)
{
_kernel = kernel;
_logger = logger;
}
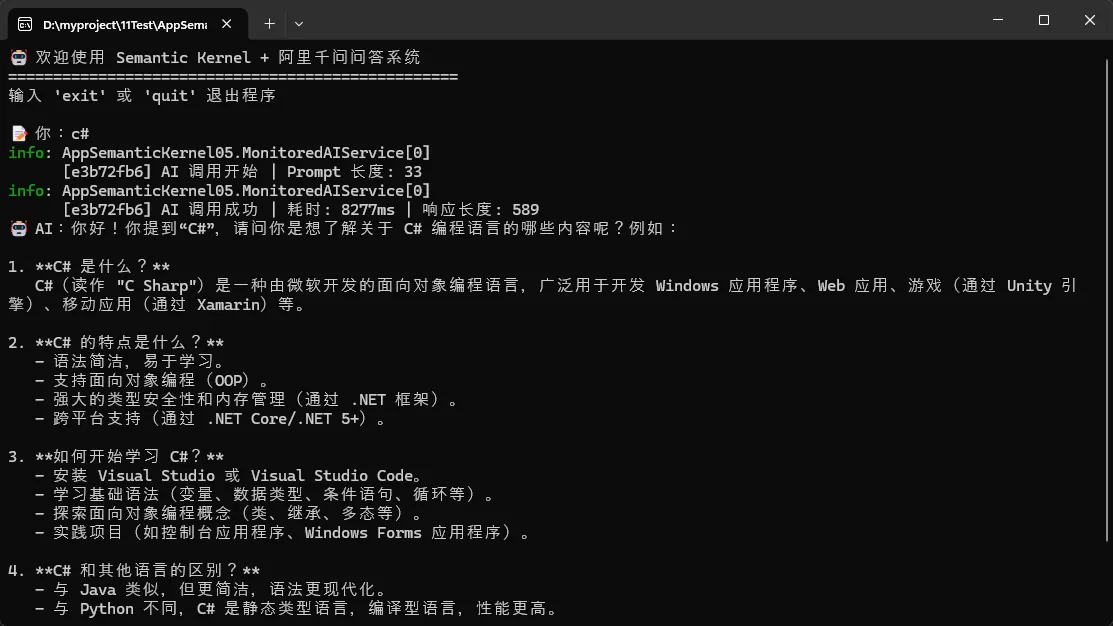
public async Task<string> InvokeWithLoggingAsync(string prompt, string traceId = null)
{
// 生成追踪 ID,便于日志关联
traceId ??= Guid.NewGuid().ToString("N")[..8];
var sw = Stopwatch.StartNew();
_logger.LogInformation(
"[{TraceId}] AI 调用开始 | Prompt 长度: {PromptLength}",
traceId, prompt.Length);
try
{
var result = await _kernel.InvokePromptAsync(prompt, new KernelArguments(
new OpenAIPromptExecutionSettings
{
MaxTokens = 2000,
Temperature = 0.7
}));
sw.Stop();
var response = result.ToString();
// 记录成功调用的关键指标
_logger.LogInformation(
"[{TraceId}] AI 调用成功 | 耗时: {ElapsedMs}ms | 响应长度: {ResponseLength}",
traceId, sw.ElapsedMilliseconds, response?.Length ?? 0);
return response ?? string.Empty;
}
catch (HttpRequestException ex)
{
sw.Stop();
_logger.LogError(ex,
"[{TraceId}] 网络请求失败 | 耗时: {ElapsedMs}ms | 错误: {ErrorMessage}",
traceId, sw.ElapsedMilliseconds, ex.Message);
throw;
}
catch (Exception ex)
{
sw.Stop();
_logger.LogError(ex,
"[{TraceId}] AI 调用异常 | 耗时: {ElapsedMs}ms | 类型: {ExceptionType}",
traceId, sw.ElapsedMilliseconds, ex.GetType().Name);
throw;
}
}
}
踩坑预警: 不要在日志里记录完整的 prompt 内容,特别是包含用户输入的场景——一方面是隐私风险,另一方面会让日志文件迅速膨胀。记录长度和关键标识即可。
