Press Ctrl+ and K to search
准确预测电力消耗对于电力系统的规划和运营至关重要。本文将详细介绍如何使用 ML.NET 构建时序预测模型,以预测全局有功功率(Global_active_power)的变化。
项目概述
- 目标:预测未来24小时的电力消耗
- 技术栈:ML.NET、C#
- 算法:单变量时序分析(SSA)
- 数据源:家庭用电量数据集
环境准备
- 创建新的 C# 控制台应用程序
- 安装必要的 NuGet 包:
XML<PackageReference Include="Microsoft.ML" Version="2.0.0" />
<PackageReference Include="Microsoft.ML.TimeSeries" Version="2.0.0" />
<PackageReference Include="CsvHelper" Version="30.0.1" />
引言
ML.NET是微软开发的开源机器学习框架,让.NET开发者能够直接在.NET应用程序中集成机器学习功能。本文将详细介绍如何使用ML.NET实现图像分类,包括环境搭建、数据准备、模型训练等完整流程。
环境准备
- Visual Studio 2022
- .NET 6.0或更高版本
- 需要安装的NuGet包:
- Microsoft.ML
- Microsoft.ML.Vision
- Microsoft.ML.ImageAnalytics
- SciSharp.TensorFlow.Redist (版本2.3.1)
项目结构
C#ImageClassification/
├── Program.cs
├── assets/ # 存放训练图片
│ ├── CD/ # 有裂缝的图片
│ └── UD/ # 无裂缝的图片
└── workspace/ # 存放模型文件
简介
矩阵因子分解(Matrix Factorization)是一种常用的推荐算法,特别适用于基于用户历史评分数据的协同过滤推荐场景。本文将详细介绍如何使用ML.NET实现一个基于矩阵因子分解的电影推荐系统。
实现步骤
1. 创建项目与安装依赖
C#// 创建.NET 6 控制台应用
// 安装NuGet包:
// - Microsoft.ML
// - Microsoft.ML.Recommender
ML.NET 是什么?
ML.NET是一个由Microsoft开发的开源机器学习框架,它允许开发者在.NET环境中创建和使用机器学习模型。ML.NET的目标是使机器学习技术更加易于访问,同时也为.NET开发者提供一个强大的工具集来整合机器学习功能到他们的应用程序中。
ML.NET的主要特点包括
- 跨平台:ML.NET支持在Windows, macOS, 和Linux上运行,并且可以在不同的.NET实现上使用,包括.NET Core, .NET Framework, 和Xamarin。
- 易于使用:ML.NET提供了一个高级API用于创建和训练模型,这使得即使没有深厚的机器学习背景知识的开发者也能够使用机器学习算法。
- 灵活性和扩展性:开发者可以使用ML.NET内置的算法,也可以通过TensorFlow, ONNX (Open Neural Network Exchange), 和其他自定义模型来扩展ML.NET的功能。
- 集成到.NET应用程序:ML.NET允许开发者在他们熟悉的.NET环境中工作,这意味着可以使用C#或F#等语言,并且可以轻松地与现有的.NET代码库和数据源集成。
- 自动化机器学习(AutoML):ML.NET提供了Model Builder和CLI工具,这些工具可以自动化模型的选择和超参数调优过程,简化了机器学习工作流程。
- 多种机器学习任务:ML.NET支持多种机器学习任务,包括但不限于分类、回归、聚类、异常检测、推荐系统和自然语言处理等。
- 性能:ML.NET在性能上进行了优化,可以处理大规模数据,并且可以在生产环境中部署。
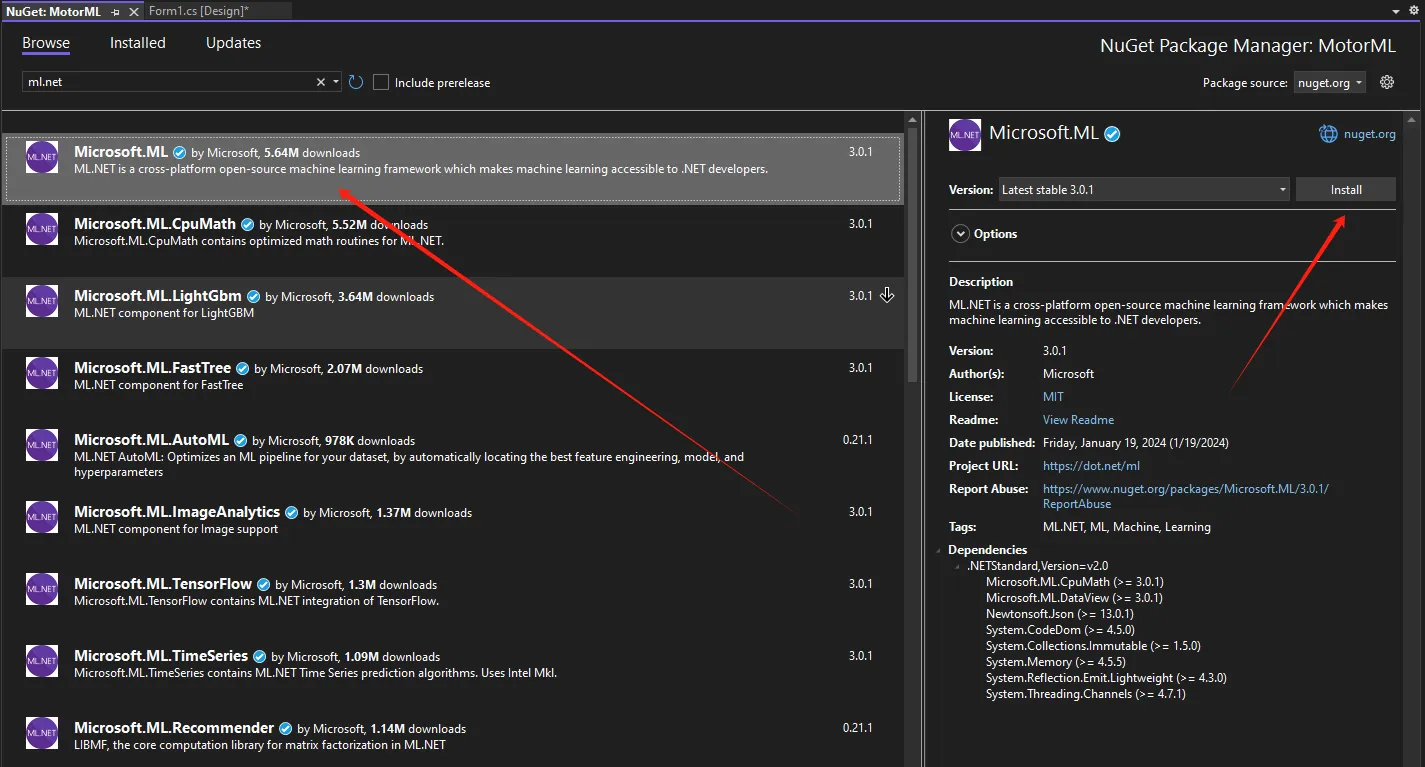
示例
nuget 安装 ML.NET
准备测试数据
加载测试数据

在Python开发过程中,尤其是数据分析和科学计算领域,我们经常需要处理大量的数组数据。想象一下,你花费了几个小时训练出的机器学习模型参数,或者经过复杂计算得到的分析结果,如果程序一关闭就全部丢失,那该有多心疼!
本文将深入解析NumPy数组的存储与加载技术,从基础的二进制存储到高级的压缩优化,帮你掌握数据持久化的核心技能。无论你是刚入门的Python开发者,还是需要处理大数据的工程师,这些实战技巧都将让你的开发效率翻倍提升。
🔍 问题分析:为什么需要数组持久化?
在实际的Python开发中,我们经常遇到以下场景:
📊 数据处理场景
- 科学计算:复杂的数值计算结果需要保存
- 机器学习:训练好的模型参数要持久化存储
- 数据分析:中间处理结果需要在不同程序间共享
- 上位机开发:传感器数据需要长期存储和分析
⚡ 性能考虑
相比于Python原生的pickle或JSON格式,NumPy提供的存储方案具有以下优势:
- 速度更快:二进制格式读写效率高
- 空间更省:专门针对数值数据优化
- 兼容性好:跨平台、跨版本兼容
💡 解决方案:NumPy存储方案全览
NumPy提供了多种数组存储方案,让我们逐一分析:
🎯 方案对比表
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
save/load | 单个数组存储 | 简单快速 | 只能存储单个数组 |
savez/load | 多个数组存储 | 可存储多个数组 | 文件稍大 |
savez_compressed | 大数据存储 | 压缩比高 | 存取速度稍慢 |
savetxt/loadtxt | 文本格式需求 | 人类可读 | 精度损失,文件大 |
🛠️ 代码实战:从入门到精通
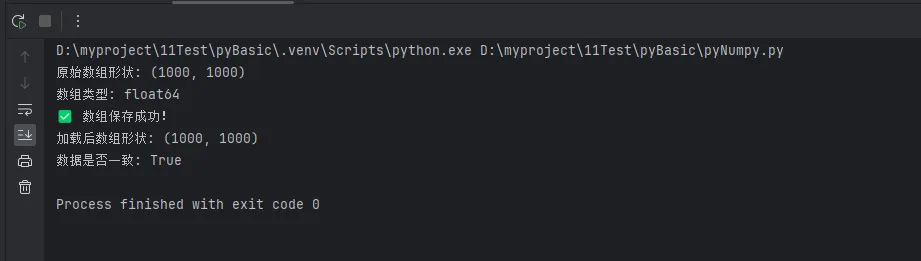
📁 基础存储:save() 和 load()
Pythonimport numpy as np
# 创建测试数据
data = np.random.rand(1000, 1000)
print(f"原始数组形状: {data.shape}")
print(f"数组类型: {data.dtype}")
# 保存数组到二进制文件
np.save('data.npy', data)
print("✅ 数组保存成功!")
# 加载数组
loaded_data = np.load('data.npy')
print(f"加载后数组形状: {loaded_data.shape}")
# 验证数据完整性
print(f"数据是否一致: {np.array_equal(data, loaded_data)}")