你是否曾经遇到过这样的问题:WPF应用运行一段时间后,内存占用越来越高,最终导致程序卡顿甚至崩溃?特别是在工业级应用中,这种问题更是致命的。今天我们就来彻底解决这个让无数开发者头疼的内存泄漏难题!
🚨 问题分析:事件订阅的隐形杀手
在WPF开发中,最常见的内存泄漏源头就是事件订阅。当你写下这样的代码时:
C#// 危险代码:容易造成内存泄漏
public class DeviceMonitor
{
public DeviceMonitor(DeviceService service)
{
service.DataUpdated += OnDataUpdated; // 强引用陷阱!
}
private void OnDataUpdated(object sender, EventArgs e)
{
// 处理逻辑
}
}
问题核心:即使 DeviceMonitor 对象不再使用,只要 DeviceService 还在运行,它就会持有对 DeviceMonitor 的强引用,导致垃圾回收器无法回收内存。
在工业监控系统中,这种问题尤其严重:
- 💀 长时间运行的服务进程
- 💀 大量的设备数据订阅
- 💀 频繁创建和销毁的监控界面
💡 解决方案:WeakEventManager救世主登场
WeakEventManager 是WPF提供的弱事件模式实现,它使用弱引用来订阅事件,避免了强引用导致的内存泄漏。
引言:数据驱动的设备健康管理
在工业4.0时代,智能预测性维护已成为制造企业降本增效的关键技术。本文将基于实际工业数据集,详细介绍如何利用C#和ML.NET构建工业设备异常检测与故障预测系统,助力企业实现从被动维修向主动预防的转变。
关键词:工业设备监控、预测性维护、C#、ML.NET、异常检测、设备故障预测、工业物联网
数据集解析:工业设备监控实况
通过分析上传的工业设备监控数据,我们可以看到系统监控了三类关键设备:
- 压缩机(Compressor):约占34%
- 涡轮机(Turbine):约占33%
- 泵(Pump):约占33%
这些设备分布在五个主要城市:亚特兰大(Atlanta)、芝加哥(Chicago)、休斯顿(Houston)、纽约(New York)和旧金山(San Francisco),其中亚特兰大和芝加哥各占约20%。
监控数据包含四个关键传感器参数:
- 温度(Temperature):范围从10.27°C到149.69°C
- 压力(Pressure):范围从3.62到79.89
- 振动(Vibration):范围从-0.43到4.99
- 湿度(Humidity):范围从10.22%到89.98%
在现代工业环境中,安全事故不仅威胁员工健康,还会导致生产损失和声誉受损。人工智能技术的发展为预防工业事故提供了新思路。本文将详细介绍如何使用Microsoft的机器学习框架ML.NET构建工厂事故预测模型,帮助企业提前识别潜在风险,采取预防措施。
ML.NET简介
ML.NET是微软开发的开源、跨平台机器学习框架,专为.NET开发者设计。它允许在.NET应用程序中集成机器学习功能,无需依赖外部服务。ML.NET支持多种机器学习算法,包括分类、回归、聚类和异常检测等,适用于各种预测场景。
工厂事故预测案例实战
接下来,我们将使用实际工厂事故数据,构建一个能够预测事故严重级别的模型。
引言
在现代商业环境中,客户流失(Customer Churn)是企业面临的一个重大挑战。了解客户流失的原因并采取有效的措施来减少流失率,对于提高企业的盈利能力至关重要。本文将介绍如何使用 ML.NET 中的 FastForestBinaryTrainer 来分析客户流失,并通过 telecom_churn.csv 文件作为训练集进行示例。
什么是 FastForestBinaryTrainer?
FastForestBinaryTrainer 是 ML.NET 中的一种基于随机森林算法的二分类训练器。它适用于处理大量特征和复杂数据集,能够有效地进行分类任务。随机森林通过构建多个决策树并结合它们的结果来提高预测的准确性和鲁棒性。
适用场景
- 高维数据:当数据集包含大量特征时,
FastForestBinaryTrainer能够有效处理。 - 非线性关系:适用于特征与目标变量之间存在复杂非线性关系的情况。
- 缺失值处理:能够处理缺失值,减少数据预处理的复杂性。
- 分类问题:特别适合二分类问题,如客户流失预测。
数据集介绍
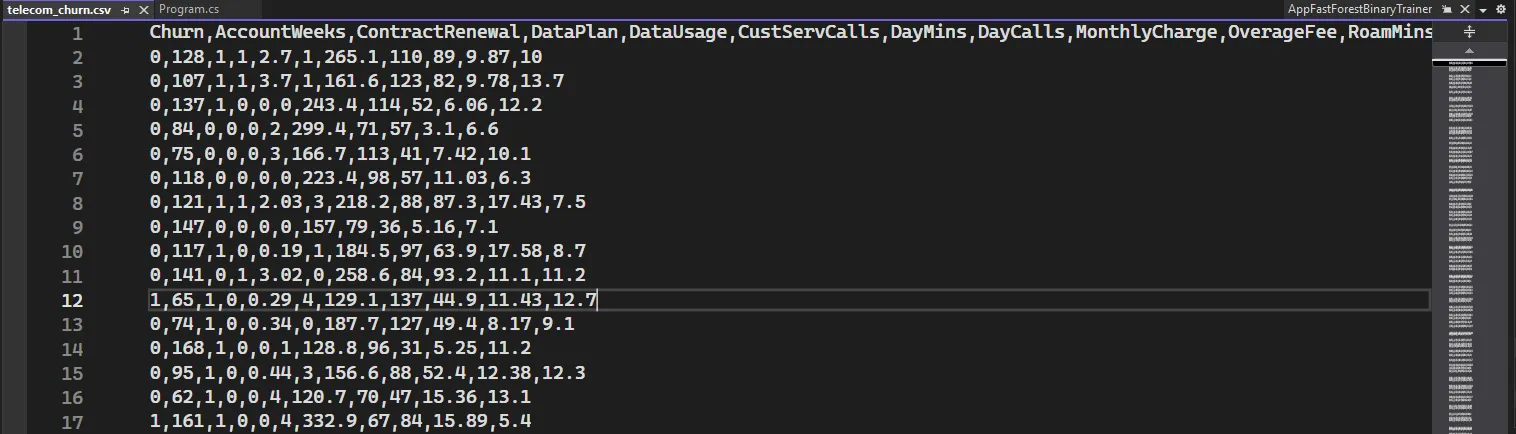
我们将使用 telecom_churn.csv 文件,该文件包含了电信公司的客户信息,包括客户的个人资料、服务使用情况和是否流失的标签。数据集的主要特征包括:
在机器学习领域,选择合适的算法和训练器对于模型的性能至关重要。ML.NET 提供了多种训练器,其中 FastTreeBinaryTrainer 是一种基于梯度提升树(Gradient Boosting Trees)的二分类训练器。本文将深入探讨 FastTreeBinaryTrainer 的适用场景,并通过详细的示例来展示其使用方法。
什么是 FastTreeBinaryTrainer?
FastTreeBinaryTrainer 是 ML.NET 中用于二分类问题的训练器。它通过构建一系列决策树来逐步改进模型的预测能力。每棵树都是在前一棵树的基础上进行训练的,旨在减少模型的误差。该训练器特别适合处理大规模数据集,并且能够处理特征之间的复杂关系。
适用场景
FastTreeBinaryTrainer 适用于以下场景:
- 大规模数据集:当数据集较大时,FastTreeBinaryTrainer 能够有效地处理并训练模型。
- 特征复杂性高:对于特征之间存在非线性关系的数据,梯度提升树能够捕捉到这些复杂的模式。
- 需要高准确率的应用:在金融欺诈检测、医疗诊断等需要高准确率的场景中,FastTreeBinaryTrainer 是一个理想的选择。
- 处理缺失值:该训练器能够自动处理缺失值,减少数据预处理的工作量。
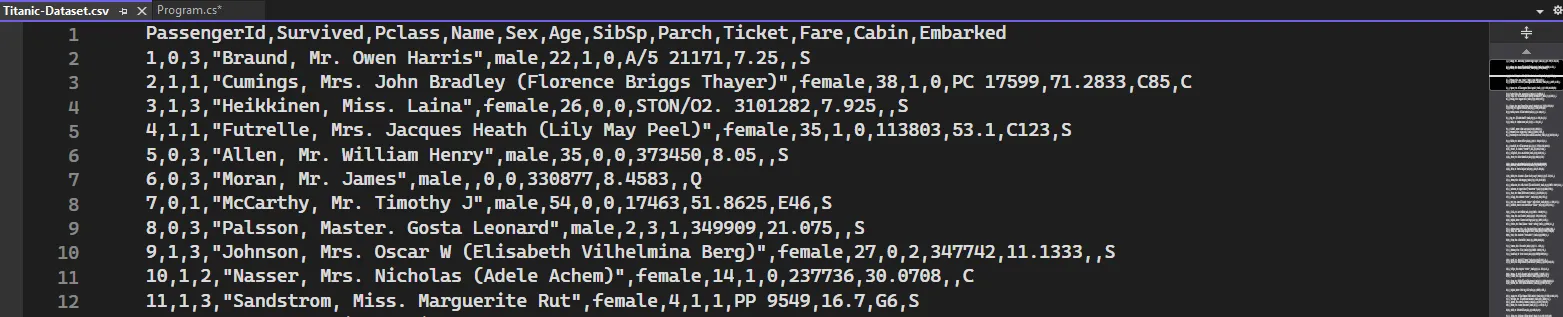
示例:使用 FastTreeBinaryTrainer 进行二分类
下面是一个使用 FastTreeBinaryTrainer 进行二分类的完整示例。我们将使用 Titanic 数据集来预测乘客是否生存。