
你是否在项目中遇到过这样的需求:需要开发一个专业的路径绘制工具,支持工业级精度和复杂路径操作?传统的GDI+性能有限,WPF又过于复杂。今天,我将带你用C#和SkiaSharp打造一个完整的工业级路径绘制系统。
本文将手把手教你:如何设计专业的UI布局、实现高性能图形渲染、处理复杂路径算法,以及导出多种工业格式(G代码、DXF等)。无论你是CAD软件开发者,还是工业控制系统工程师,这套解决方案都能为你节省大量开发时间。
💡 问题分析:工业绘图软件的核心痛点
🔍 传统方案的局限性
在开发工业级绘图软件时,我们常常面临这些挑战:
性能瓶颈:GDI+在处理大量图形元素时性能急剧下降
精度问题:浮点运算误差影响工业级精度要求
格式兼容:需要支持多种工业标准格式输出
UI复杂性:专业软件需要丰富的交互体验
🎯 SkiaSharp的优势
SkiaSharp作为Google Skia的.NET绑定,为我们提供了:
- 硬件加速:GPU渲染支持,性能提升10倍以上
- 跨平台:Windows、macOS、Linux全平台支持
- 工业精度:支持亚像素级精确渲染
- 丰富API:完整的2D图形绘制能力
🏗️ 系统架构设计
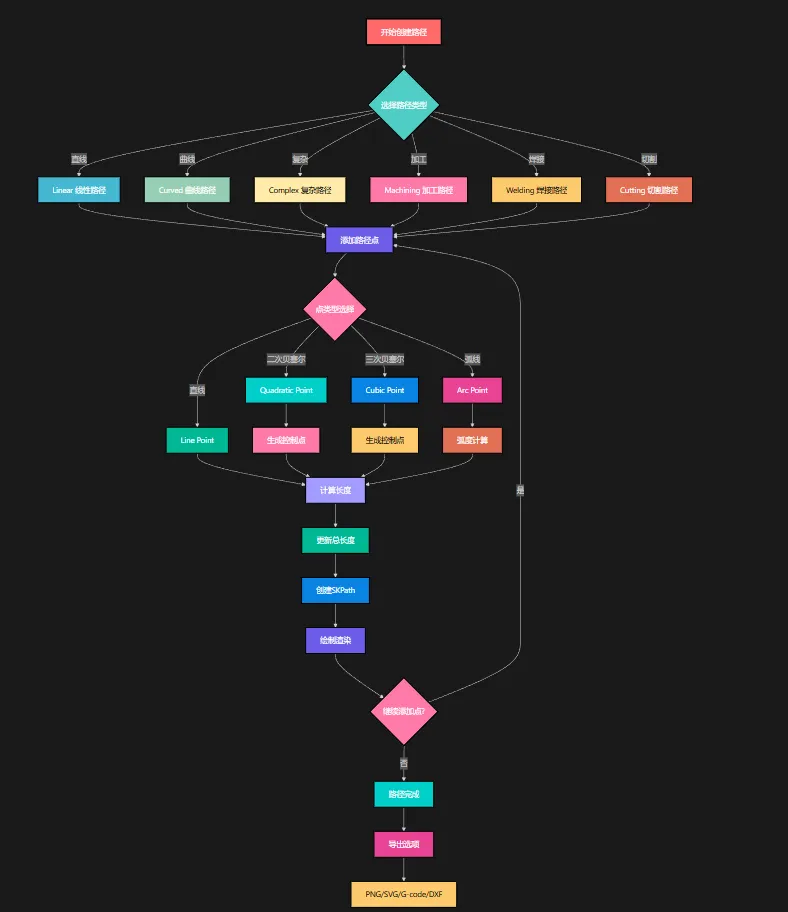
📋 核心类结构
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using SkiaSharp;
namespace AppIndustrialPathDrawing.Models
{
public class PathPoint
{
public float X { get; set; }
public float Y { get; set; }
public PathPointType Type { get; set; }
public float[] ControlPoints { get; set; }
public string Description { get; set; }
public DateTime CreatedTime { get; set; }
public PathPoint()
{
CreatedTime = DateTime.Now;
Type = PathPointType.Line;
}
public PathPoint(float x, float y, PathPointType type = PathPointType.Line) : this()
{
X = x;
Y = y;
Type = type;
}
public SKPoint ToSKPoint()
{
return new SKPoint(X, Y);
}
public override string ToString()
{
return $"({X:F2}, {Y:F2}) - {Type}";
}
}
public enum PathPointType
{
Move, // 移动到点
Line, // 直线到点
Curve, // 曲线到点
Arc, // 弧线到点
Cubic, // 三次贝塞尔曲线
Quadratic // 二次贝塞尔曲线
}
}
你是否曾经为了部署一个AI模型而头疼不已?训练好的模型在不同平台间迁移困难,性能优化复杂,部署成本居高不下......作为C#开发者,我们迫切需要一个高效、跨平台的AI推理解决方案。
今天,我将带你用最简单的方式搭建第一个ONNX Runtime程序,让你在5分钟内体验到AI模型部署的魅力。本文将解决初学者最关心的三个问题:如何快速上手、常见坑点避免、实际项目应用。
🔍 为什么选择ONNX Runtime?
核心痛点分析
在传统的AI模型部署中,开发者通常面临以下挑战:
- 平台兼容性差:不同框架训练的模型难以跨平台使用
- 性能优化复杂:CPU和GPU优化需要大量专业知识
- 部署成本高:需要安装庞大的深度学习框架
ONNX Runtime完美解决了这些问题:它是微软开源的高性能机器学习推理引擎,支持多种硬件平台,专为生产环境优化。
🛠️ 环境准备
安装NuGet包
C#// 安装ONNX Runtime CPU版本
dotnet add package Microsoft.ML.OnnxRuntime --version 1.23.2
⚠️ 重要提醒:选择CPU版本还是GPU版本要根据实际需求,初学者建议先从CPU版本开始。
准备测试模型
下载一个简单的ONNX模型用于测试(建议使用mnist手写数字识别模型):
C#// 模型文件放在项目根目录下
// mnist-8.onnx (28x28像素的手写数字识别模型)
🔥 第一个ONNX Runtime程序
核心代码实现
C#using Microsoft.ML.OnnxRuntime;
using Microsoft.ML.OnnxRuntime.Tensors;
namespace AppOnnx
{
internal class Program
{
static void Main(string[] args)
{
try
{
// 步骤1:初始化推理会话
var sessionOptions = new SessionOptions();
using var session = new InferenceSession("mnist-8.onnx", sessionOptions);
// 检查模型的输入输出信息
PrintModelInfo(session);
// 步骤2:准备输入数据
var inputData = CreateSampleInput();
// 获取正确的输入节点名称
var inputName = session.InputMetadata.Keys.First();
var inputs = new List<NamedOnnxValue>
{
NamedOnnxValue.CreateFromTensor(inputName, inputData)
};
// 步骤3:执行推理
using var results = session.Run(inputs);
// 步骤4:处理输出结果
var output = results.FirstOrDefault()?.AsTensor<float>();
if (output != null)
{
var predictedDigit = GetPredictedDigit(output);
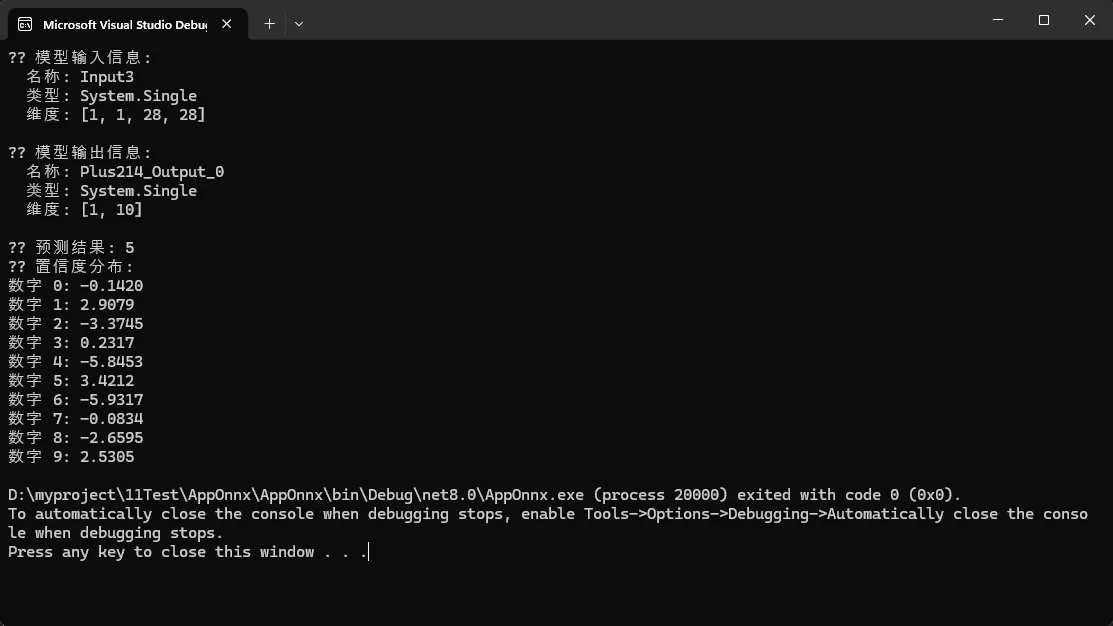
Console.WriteLine($"🎉 预测结果: {predictedDigit}");
Console.WriteLine($"📊 置信度分布:");
PrintConfidenceScores(output);
}
else
{
Console.WriteLine("❌ 无法获取输出结果");
}
}
catch (Exception ex)
{
Console.WriteLine($"❌ 执行出错: {ex.Message}");
Console.WriteLine($"📍 堆栈跟踪: {ex.StackTrace}");
}
}
// 打印模型信息
private static void PrintModelInfo(InferenceSession session)
{
Console.WriteLine("📋 模型输入信息:");
foreach (var input in session.InputMetadata)
{
Console.WriteLine($" 名称: {input.Key}");
Console.WriteLine($" 类型: {input.Value.ElementType}");
Console.WriteLine($" 维度: [{string.Join(", ", input.Value.Dimensions)}]");
}
Console.WriteLine("\n📋 模型输出信息:");
foreach (var output in session.OutputMetadata)
{
Console.WriteLine($" 名称: {output.Key}");
Console.WriteLine($" 类型: {output.Value.ElementType}");
Console.WriteLine($" 维度: [{string.Join(", ", output.Value.Dimensions)}]");
}
Console.WriteLine();
}
// 创建示例输入数据(模拟28x28的手写数字图像)
private static Tensor<float> CreateSampleInput()
{
// 标准MNIST输入格式:[batch_size, channels, height, width] 或 [batch_size, height, width, channels]
var tensor = new DenseTensor<float>(new[] { 1, 1, 28, 28 });
// 模拟一个简单的数字"1"
for (int i = 10; i < 18; i++)
{
for (int j = 12; j < 16; j++)
{
if (i < 28 && j < 28) // 添加边界检查
{
tensor[0, 0, i, j] = 1.0f;
}
}
}
return tensor;
}
// 获取预测结果
private static int GetPredictedDigit(Tensor<float> output)
{
if (output == null || output.Length == 0) return -1;
var maxIndex = 0;
var maxValue = float.MinValue;
// 安全的索引访问
var span = output.ToArray(); // 转换为数组进行安全访问
for (int i = 0; i < span.Length && i < 10; i++) // MNIST有10个类别(0-9)
{
if (span[i] > maxValue)
{
maxValue = span[i];
maxIndex = i;
}
}
return maxIndex;
}
// 打印置信度分数
private static void PrintConfidenceScores(Tensor<float> output)
{
if (output == null || output.Length == 0) return;
var span = output.ToArray();
var length = Math.Min(span.Length, 10); // 确保不超过10个类别
for (int i = 0; i < length; i++)
{
Console.WriteLine($"数字 {i}: {span[i]:F4}");
}
}
}
}
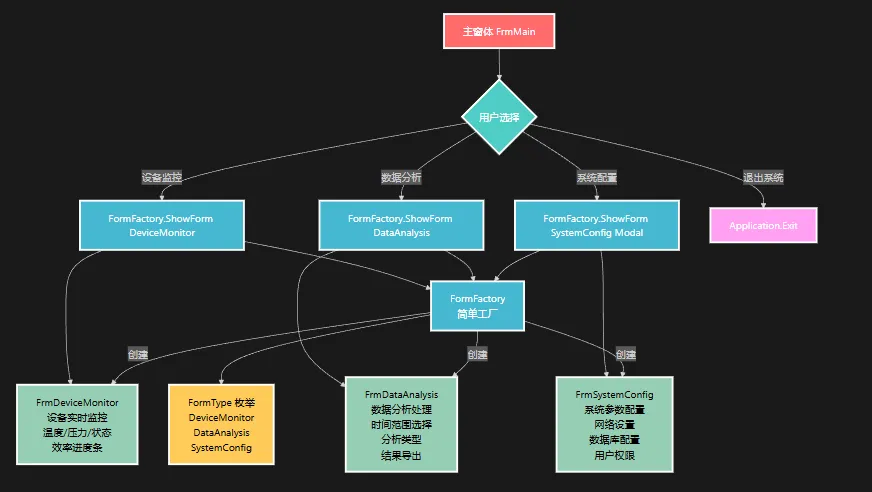
你是否曾经为了创建不同类型的窗体而写了一堆重复代码?每次新增窗体都要修改调用代码,维护起来头疼不已?作为一名资深C#开发者,我发现很多同行在构建企业级WinForms应用时,都会遇到窗体管理混乱、代码耦合度高的问题。
今天,我将通过一个完整的工业生产管理系统案例,手把手教你如何用简单工厂模式优雅地解决这些痛点,让你的代码更加清晰、可维护。文章末尾还有完整的可运行项目代码,绝对干货满满!
🎯 痛点分析:传统窗体创建的三大问题
问题1:代码重复冗余
C#// 传统方式:到处都是这样的代码
private void button1_Click(object sender, EventArgs e)
{
var form = new DeviceMonitorForm();
form.Show();
}
private void button2_Click(object sender, EventArgs e)
{
var form = new DataAnalysisForm();
form.Show();
}
// 更多重复代码...
问题2:维护困难
当需要给所有窗体添加统一的初始化逻辑时,你需要修改每个创建窗体的地方,工作量巨大。
问题3:扩展性差
新增窗体类型时,需要在多个地方修改代码,违反了开闭原则。
🚩 设计流程
你是否遇到过这样的场景:处理大量数据时,CPU只用了一个核心,其他核心在"摸鱼"?或者明明是简单的数组计算,却耗时惊人?
今天我要告诉你一个颠覆认知的事实:即使在单核上,我们也能实现"并行计算"!秘密武器就是 SIMD(Single Instruction, Multiple Data)技术。通过 C# 的 System.Numerics 命名空间,我们可以让 CPU 在一个指令周期内处理多个数据,性能提升可达 4-8 倍!
本文将从实际问题出发,带你掌握 SIMD 在 C# 中的应用,让你的程序真正"飞起来"。
🔍 问题分析:为什么传统循环这么慢?
传统串行处理的痛点
在传统的 C# 开发中,我们习惯用循环处理数组:
C#// 传统方式:逐个元素处理
public static void TraditionalAdd(float[] a, float[] b, float[] result)
{
for (int i = 0; i < a.Length; i++)
{
result[i] = a[i] + b[i]; // 每次只处理一个元素
}
}
问题在哪?
- CPU 每个时钟周期只处理一个数据
- 现代 CPU 的向量寄存器(128位、256位)被浪费
- 内存带宽利用率低
💡 SIMD 解决方案:一次处理多个数据
🎯 方案一:使用 Vector 进行基础向量化
C#using System.Numerics;
using System;
using System.Diagnostics;
namespace AppSimd
{
internal class Program
{
static void Main(string[] args)
{
// 测试数据大小
int arraySize = 10000000;
// 创建测试数组
float[] a = new float[arraySize];
float[] b = new float[arraySize];
float[] result = new float[arraySize];
float[] resultNormal = new float[arraySize];
// 初始化测试数据
Random random = new Random(42);
for (int i = 0; i < arraySize; i++)
{
a[i] = (float)random.NextDouble() * 100;
b[i] = (float)random.NextDouble() * 100;
}
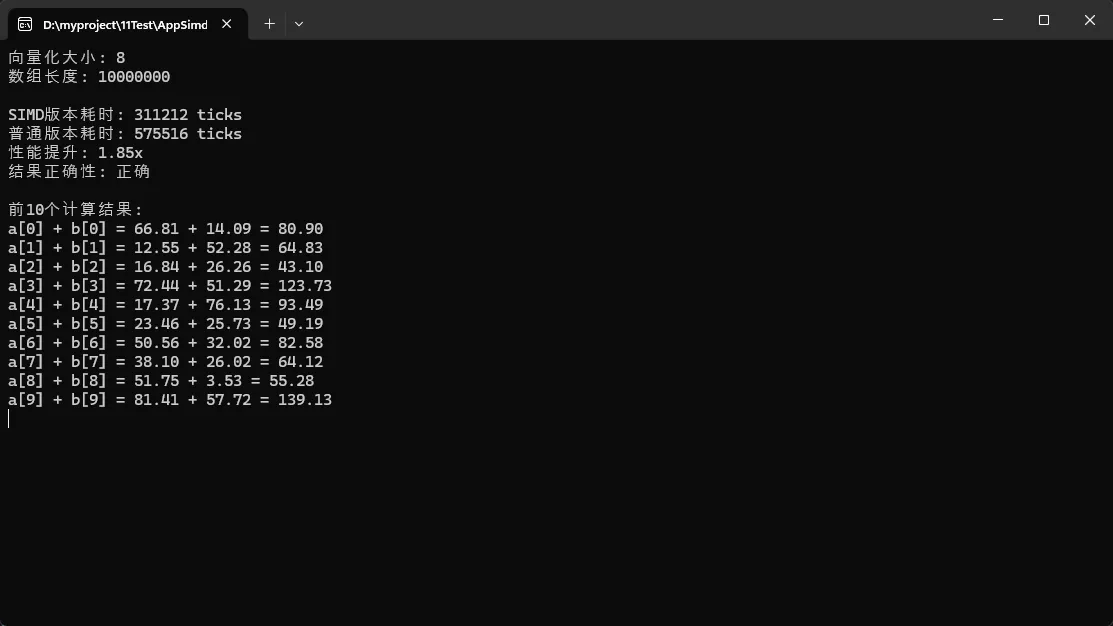
Console.WriteLine($"向量化大小: {Vector<float>.Count}");
Console.WriteLine($"数组长度: {arraySize}");
Console.WriteLine();
// 性能测试 - SIMD版本
Stopwatch sw = Stopwatch.StartNew();
VectorizedAdd(a, b, result);
sw.Stop();
long simdTime = sw.ElapsedTicks;
// 性能测试 - 普通版本
sw.Restart();
NormalAdd(a, b, resultNormal);
sw.Stop();
long normalTime = sw.ElapsedTicks;
// 验证结果正确性
bool isCorrect = VerifyResults(result, resultNormal);
// 输出结果
Console.WriteLine($"SIMD版本耗时: {simdTime} ticks");
Console.WriteLine($"普通版本耗时: {normalTime} ticks");
Console.WriteLine($"性能提升: {(double)normalTime / simdTime:F2}x");
Console.WriteLine($"结果正确性: {(isCorrect ? "正确" : "错误")}");
// 显示前几个结果作为示例
Console.WriteLine("\n前10个计算结果:");
for (int i = 0; i < 10; i++)
{
Console.WriteLine($"a[{i}] + b[{i}] = {a[i]:F2} + {b[i]:F2} = {result[i]:F2}");
}
Console.ReadKey();
}
public static void VectorizedAdd(float[] a, float[] b, float[] result)
{
int vectorSize = Vector<float>.Count; // 通常是 4 或 8
int vectorizedLength = a.Length - (a.Length % vectorSize);
// 向量化处理部分
for (int i = 0; i < vectorizedLength; i += vectorSize)
{
var vectorA = new Vector<float>(a, i);
var vectorB = new Vector<float>(b, i);
var vectorResult = vectorA + vectorB; // 一次处理多个元素!
vectorResult.CopyTo(result, i);
}
// 处理剩余元素
for (int i = vectorizedLength; i < a.Length; i++)
{
result[i] = a[i] + b[i];
}
}
// 普通加法实现(用于性能对比)
public static void NormalAdd(float[] a, float[] b, float[] result)
{
for (int i = 0; i < a.Length; i++)
{
result[i] = a[i] + b[i];
}
}
// 验证两种方法的结果是否一致
private static bool VerifyResults(float[] result1, float[] result2)
{
if (result1.Length != result2.Length) return false;
for (int i = 0; i < result1.Length; i++)
{
if (Math.Abs(result1[i] - result2[i]) > 1e-6f)
{
return false;
}
}
return true;
}
}
}
作为C#开发者,你是否遇到过这样的困扰:用户希望自定义界面字体和颜色,但自己写选择器太复杂?或者想要快速实现类似Office软件那样的字体颜色选择功能?
今天我们来深入探讨C# WinForms中的FontDialog和ColorDialog——两个能让你的应用程序瞬间变得专业的神器!本文将通过实战案例,教你如何优雅地实现用户界面定制功能。
🔍 问题分析:为什么需要标准对话框?
在WinForms开发中,用户界面定制是提升用户体验的关键。传统做法是自己写颜色选择器和字体选择器,但这样做有三个致命问题:
- 开发成本高:需要大量代码实现复杂的UI逻辑
- 用户体验差:界面不统一,用户需要重新学习操作
- 兼容性问题:难以处理各种字体和颜色的边界情况
而使用系统标准对话框,用户熟悉操作流程,开发效率也大大提升。
🎯 解决方案:掌握两大核心对话框
🔤 FontDialog:让文字更有个性
FontDialog是字体选择的完美解决方案,它不仅能选择字体,还能同时设置大小、样式和颜色。
核心属性速览
C#FontDialog fontDialog = new FontDialog();
fontDialog.ShowColor = true; // 显示颜色选择
fontDialog.FontMustExist = true; // 只允许选择存在的字体
fontDialog.AllowVectorFonts = true; // 允许矢量字体
fontDialog.MaxSize = 72; // 最大字号
fontDialog.MinSize = 8; // 最小字号