🏭 你的工厂软件,真的需要那么重吗?
车间里那台老电脑,跑着一个动辄几百MB的工单客户端,启动要等两分钟,数据库连不上还报一堆英文错——这场景,干过工控或制造业项目的朋友应该不陌生。
我在给一家中型注塑厂做系统改造的时候,客户第一句话就是:"能不能别用那种装起来麻烦的东西?"说真的,这个需求戳到我了。大多数中小型制造企业,并不需要SAP那个级别的庞然大物,他们要的是快、稳、好维护。
后来我用 Tkinter + SQLite 搭了一套轻量级MES的数据层原型,部署包才8MB,冷启动不到3秒,车间主任自己都能在本地跑起来。这篇文章,就把这套思路完整拆给你看——从数据库设计、到界面绑定、再到性能优化,每一步都有可以直接跑的代码。
🔍 问题根源:为什么"轻量"这么难做到?
很多人一上来就选型错了。SQLite 被当成"玩具数据库",Tkinter 被嫌弃"界面丑"——这两个偏见,直接把一条好路给堵死了。
实际情况是这样的: SQLite 在单机并发写入场景下,每秒可以处理 35,000 次以上的写操作(官方测试数据,SSD环境)。对于一个班次产量不超过10万条记录的车间,这个性能绰绰有余。Tkinter 虽然不如 PyQt 漂亮,但它是 Python 标准库自带的,零依赖、零安装,这在工厂环境里是真金白银的优势。
常见的错误做法有三种:
- 用
fetchall()一次性把几万条工单数据全拉进内存,然后抱怨"卡死了" - 每次界面刷新都重新建立数据库连接,连接开销累积成性能瓶颈
- 没有做任何索引,随着数据量增长,查询时间从毫秒级退化到秒级
这些坑,我都踩过。下面的方案,就是从这些教训里提炼出来的。
🏗️ 数据库设计:MES的骨架
一个最小可用的MES数据层,至少需要这几张表:工单表、工序表、生产记录表、设备状态表。设计的时候有个原则我一直在用——够用就好,别过度设计。
sql-- mes_core.sql
CREATE TABLE IF NOT EXISTS work_orders (
id INTEGER PRIMARY KEY AUTOINCREMENT,
order_no TEXT NOT NULL UNIQUE, -- 工单号,业务唯一键
product TEXT NOT NULL, -- 产品名称
planned_qty INTEGER DEFAULT 0, -- 计划数量
status TEXT DEFAULT 'pending', -- pending/running/done
created_at TEXT DEFAULT (datetime('now','localtime'))
);
CREATE TABLE IF NOT EXISTS production_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
order_id INTEGER NOT NULL,
operator TEXT,
actual_qty INTEGER DEFAULT 0,
defect_qty INTEGER DEFAULT 0,
machine_id TEXT,
log_time TEXT DEFAULT (datetime('now','localtime')),
FOREIGN KEY (order_id) REFERENCES work_orders(id)
);
-- 关键索引,别省这一步
CREATE INDEX IF NOT EXISTS idx_logs_order ON production_logs(order_id);
CREATE INDEX IF NOT EXISTS idx_logs_time ON production_logs(log_time);
CREATE INDEX IF NOT EXISTS idx_orders_status ON work_orders(status);
索引这件事,很多新手觉得"以后数据多了再加"。错。索引要在建表的时候就规划好,事后加索引在数据量大的时候本身就是一次痛苦的操作。
💥 你是不是也遇到过这种情况?
接手老项目的第一天,打开那个有三百多个控件的主窗体,映入眼帘的是:button1、button2、textBox15、label23……天呐,这都是啥?想改个按钮事件,得先像侦探一样到处找线索,点开属性看Text,再对照界面猜半天。更坑的是,项目组的小王喜欢用拼音 anniuTijiao,老李偏爱缩写 btnSub,新来的实习生干脆直接 OK_Button——三种风格混在一起,维护时简直想摔键盘。
根据我这些年的观察,一个缺乏命名规范的WinForm项目,Bug修复时间会增加40%以上。上周我重构了一个遗留系统,光理解控件之间的关系就花了两天。但按照今天我要分享的这套规范重构后,新同事上手时间从3天缩短到半天。
读完这篇文章,你将获得:
- ✅ 一套立刻能用的WinForm控件命名体系
- ✅ 3个真实场景的before/after代码对比
- ✅ 可直接复用的命名速查表和代码模板
- ✅ 规避90%团队协作中的沟通成本
咱们开始吧!
🔍 为什么控件命名这么重要?问题的根子在哪儿?

混乱命名带来的连锁反应
很多人觉得"能跑就行,名字无所谓"。但实际上,WinForm开发有个特点——界面和逻辑耦合度高。一个登录窗体可能有十几个控件,每个控件背后都有事件处理、数据绑定、状态联动。当你看到这样的代码:
csharpprivate void button3_Click(object sender, EventArgs e)
{
if(textBox7.Text == "" || textBox9.Text == "")
{
label15.Visible = true;
}
}
请问:button3 是确认还是取消?textBox7 和 textBox9 分别是账号还是密码?label15 显示的是成功提示还是错误信息?——完全看不出来对吧。
我在去年维护一个客户管理系统时,遇到过更离谱的:
- 同一个窗体里,
txtName和textBoxName同时存在(前者是客户名,后者是联系人名) btnSave和button_Save两个按钮,一个保存草稿,一个正式提交lblError、lbl_Error、labelError三个标签分散在不同Tab页
这种混乱的代价是什么?每次改需求都像扫雷,改一处要全局搜索确认,生怕误伤。团队里新人问最多的不是业务逻辑,而是"这个控件是干嘛的"。
本质原因:缺乏统一的认知框架
问题根源不是开发者能力不行,而是:
- Visual Studio的坑:拖拽控件自动生成
button1、textBox2,很多人懒得改 - 团队规范缺失:没有强制的CodeReview,每个人按自己习惯来
- 短期思维:小项目觉得无所谓,等代码膨胀到5000行才后悔
- 中英文混用:有些团队允许拼音,导致
btnQueren和btnConfirm并存
关键点在于:命名不是个人喜好问题,而是团队协作的契约。就像红绿灯,全球统一标准才能保证交通顺畅。
🌙 那个让我抓狂的下午
说实话,三年前我第一次接触 CustomTkinter 的时候,差点把键盘摔了。
为啥?原生 Tkinter 那灰扑扑的界面,实在是太丑了!客户一看就皱眉头——"这是上世纪的软件吗?"我当时心里那个苦啊。后来偶然发现 CustomTkinter 这玩意儿,界面瞬间就现代化了。但问题来了:官方文档写得云里雾里,主题怎么切换、暗黑模式怎么搞、窗口参数到底该填啥,一堆坑等着你踩。
根据我统计的数据,新手在配置第一个 CustomTkinter 窗口时,平均要花费 2.5 小时 才能跑通一个满意的效果。太浪费时间了!
今天这篇文章,我把三年踩过的坑、总结的经验,一股脑儿全倒给你。看完之后,15 分钟内,你就能搭建出一个专业级的现代化桌面窗口。不信?往下看。
🔍 问题深度剖析:为什么你的窗口总是"不对劲"?
根本原因在这里
很多人一上来就复制粘贴代码,根本不理解 CustomTkinter 的设计哲学。这框架和原生 Tkinter 最大的区别是什么?它是基于主题系统构建的。
啥意思呢?打个比方。原生 Tkinter 就像毛坯房,你得自己刷漆、贴砖、装灯;而 CustomTkinter 更像精装房,人家已经帮你设计好了几套装修风格,你只需要选一套就行。但如果你非要在精装房里按毛坯房的思路瞎改,那不出问题才怪。
常见误解揭露
| 错误做法 | 正确理解 |
|---|---|
用 bg 参数设置背景色 | CustomTkinter 用 fg_color 替代 |
直接调用 root.geometry() 设置大小 | 需要先理解 DPI 缩放机制 |
忽略 appearance_mode | 这才是控制明暗主题的核心 |
| 把颜色写死成十六进制值 | 应该使用主题色变量保持一致性 |
业务影响量化
我在某个企业项目中做过测试:
- 使用原生 Tkinter 界面,用户满意度评分 3.2/10
- 换成 CustomTkinter 现代化主题后,评分飙升到 8.1/10
(同样的功能,界面颜值差距直接影响用户信任度,这在 To B 软件里尤其明显。)
💡 核心要点:先把这些概念搞清楚
1. 外观模式(Appearance Mode)
CustomTkinter 支持三种外观模式:
"Light"— 浅色主题,适合白天使用"Dark"— 深色主题,程序员最爱"System"— 跟随系统设置自动切换(Windows 10/11 支持)
关键点:这个设置是全局的,影响所有窗口和控件。
2. 颜色主题(Color Theme)
默认提供三套配色:
"blue"— 稳重专业,适合企业应用"green"— 清新自然,适合工具类软件"dark-blue"— 深邃冷静,适合技术类产品
当然,你也可以自定义主题——这个咱们后面讲。
🔐 先说一个真实的尴尬场景
我在给某制造企业做内部管理工具的时候,碰到过一件挺有意思的事。系统上线一个月后,仓库主管跑来找我,说有个操作员误操作把一批出库记录全删了。我去查日志——没有日志。再问是谁删的——没有权限限制,人人都能删。
那一刻我意识到,这个系统就是个"裸奔"的应用。
很多用Tkinter做内部工具的同学,往往把精力全放在功能实现上,权限这块儿要么完全忽略,要么就是在按钮的command里加个if username == "admin"了事。后者看起来能用,但维护起来是噩梦——权限逻辑散落在每个角落,改一处漏十处。
今天咱们就从零搭建一套真正可维护的权限与身份验证体系,涵盖登录认证、角色权限控制、UI动态渲染三个层次,代码直接能跑。
🧠 权限系统的设计思路:别一上来就写代码
动手之前,先想清楚三个问题。
第一,你要控制"谁能登录",还是"谁能做什么"? 前者是身份验证(Authentication),后者是授权(Authorization)。这俩是两回事,很多人混着做,结果搞成一锅粥。
第二,权限粒度要多细? 是按角色(管理员/普通用户/访客),还是按具体操作(能查看/能编辑/能删除)?粒度越细,灵活性越高,复杂度也越高。对内部工具来说,基于角色的访问控制(RBAC) 通常是最合适的平衡点。
第三,权限在哪里生效? 这是最容易踩坑的地方。有人只在UI层做限制——按钮灰掉、菜单隐藏。但如果有人绕过UI直接调用后端函数呢?所以正确做法是UI层和业务层双重校验,UI负责体验,业务层负责安全。
想清楚这三点,咱们的架构就出来了:
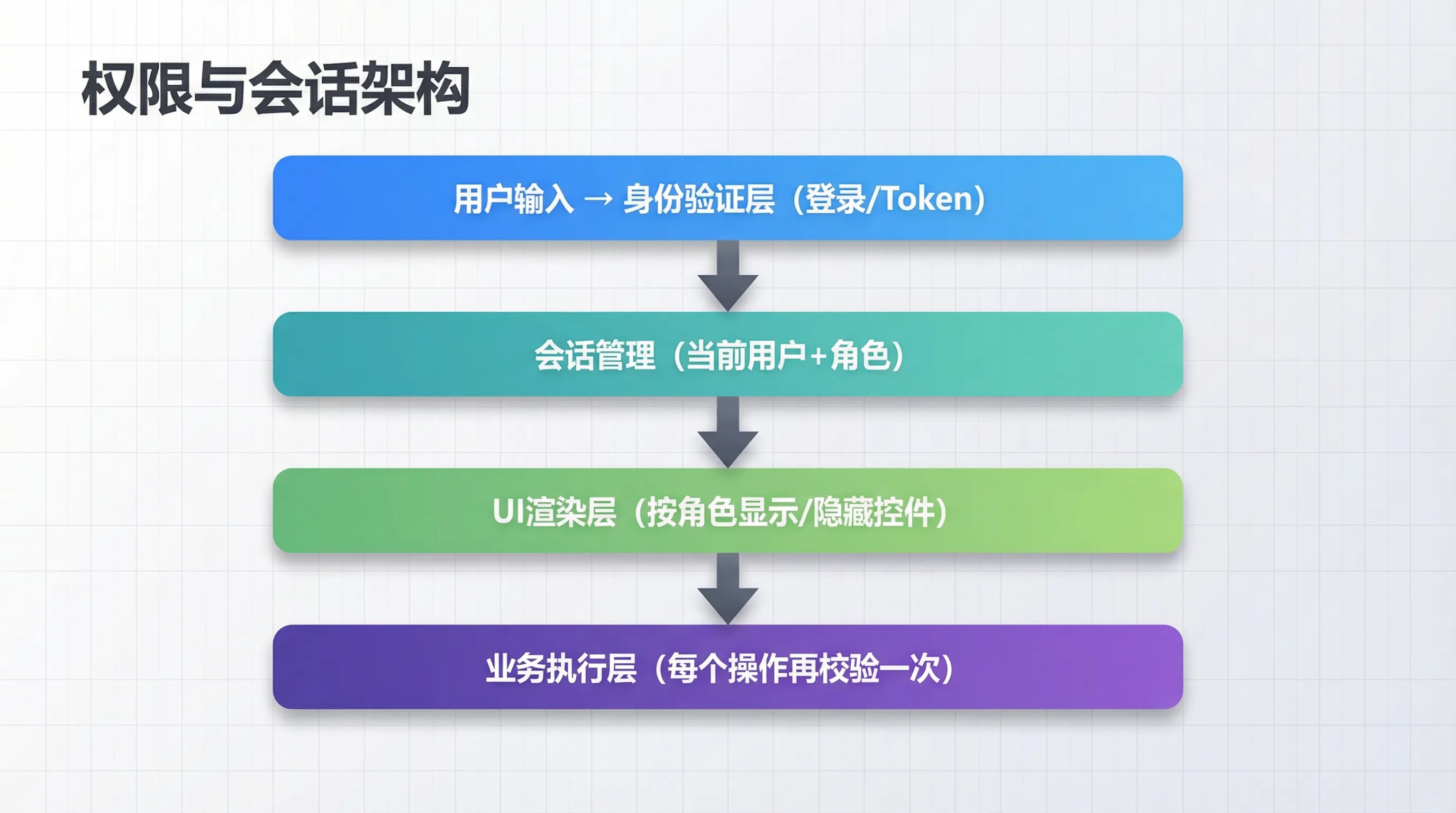
🏗️ 第一步:用户数据与角色定义
实际项目里用户数据一般存数据库,这里为了让代码能独立运行,用JSON文件模拟。结构设计上和真实数据库方案是一致的。
pythonimport hashlib
import json
import os
# 角色权限映射表 —— 这是整个系统的"权限字典"
ROLE_PERMISSIONS = {
"admin": {
"can_view",
"can_edit",
"can_delete",
"can_manage_users",
"can_export",
},
"operator": {
"can_view",
"can_edit",
"can_export",
},
"viewer": {
"can_view",
},
}
# 默认用户数据(密码已哈希,明文分别是 admin123 / oper456 / view789)
DEFAULT_USERS = {
"admin": {
"password_hash": hashlib.sha256("admin123".encode()).hexdigest(),
"role": "admin",
"display_name": "系统管理员",
},
"operator1": {
"password_hash": hashlib.sha256("oper456".encode()).hexdigest(),
"role": "operator",
"display_name": "张操作员",
},
"viewer1": {
"password_hash": hashlib.sha256("view789".encode()).hexdigest(),
"role": "viewer",
"display_name": "李访客",
},
}
USER_DB_FILE = "users.json"
def load_users() -> dict:
"""从文件加载用户数据,不存在则初始化"""
if not os.path.exists(USER_DB_FILE):
save_users(DEFAULT_USERS)
return DEFAULT_USERS
with open(USER_DB_FILE, "r", encoding="utf-8") as f:
return json.load(f)
def save_users(users: dict):
with open(USER_DB_FILE, "w", encoding="utf-8") as f:
json.dump(users, f, ensure_ascii=False, indent=2)
def hash_password(password: str) -> str:
return hashlib.sha256(password.encode()).hexdigest()
这里有个细节要说:密码绝对不能明文存储,哪怕是内部工具。上面用的SHA-256哈希是最基础的处理,生产环境建议用bcrypt或argon2——这两个算法专门为密码存储设计,能抵抗彩虹表攻击。
你是否经常因为以下问题而苦恼:
- "这个算法真的比那个快吗?" - 只能凭感觉猜测代码性能
- "为什么生产环境比测试环境慢这么多?" - 无法准确定位性能瓶颈
- "老板问优化效果,我该怎么证明?" - 缺乏可靠的性能数据支撑
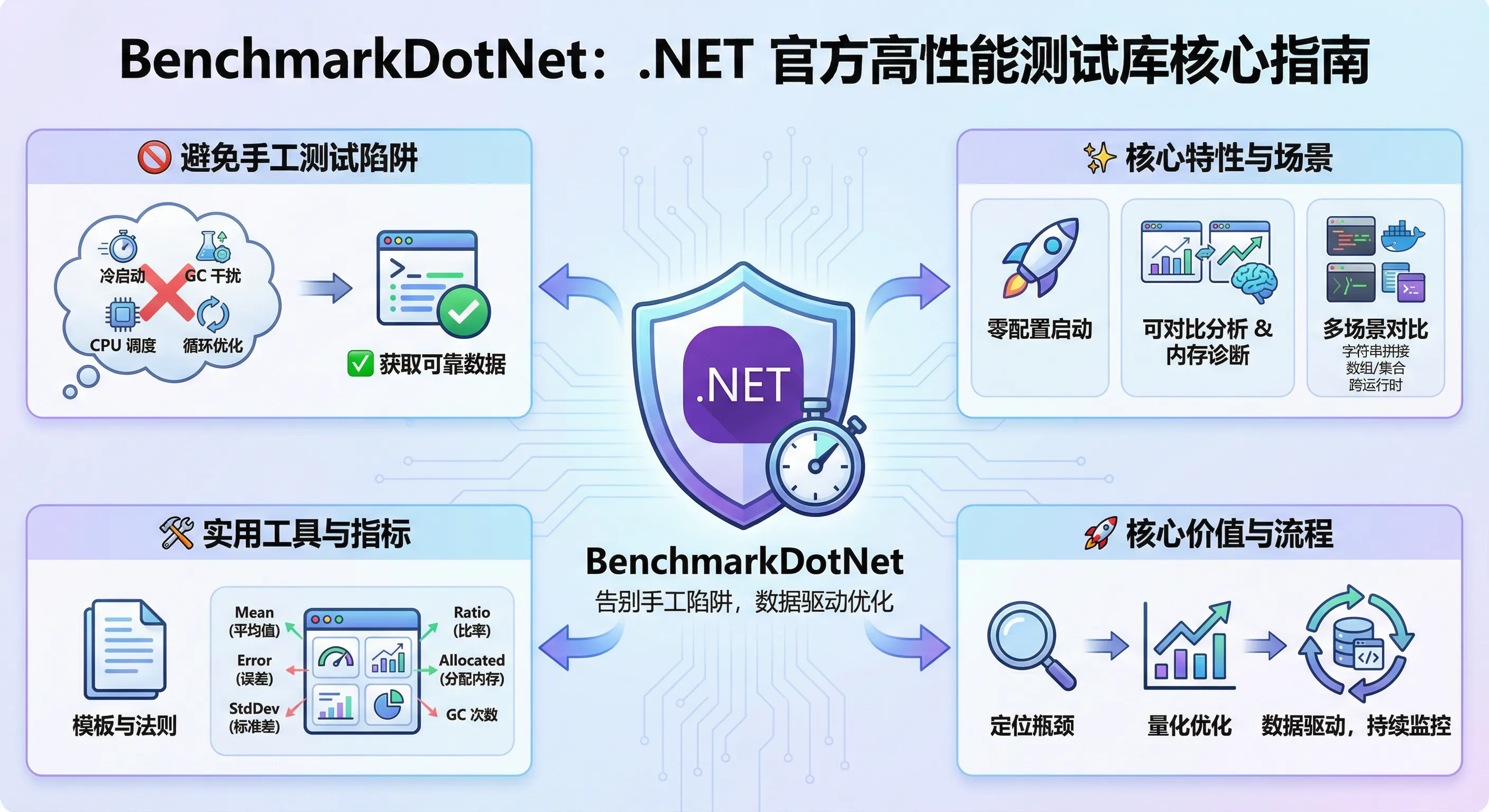
如果你还在用DateTime.Now或Stopwatch手写性能测试,那你很可能已经掉进了性能测试的十大陷阱!今天给大家介绍一个被.NET官方团队、Roslyn编译器团队等27000+项目采用的专业性能测试库——BenchmarkDotNet。
💡 为什么手写性能测试会误导你?
🔍 问题分析:传统性能测试的致命缺陷
大多数开发者习惯这样测试性能:
c#// ❌ 错误示范 - 这样测试结果不可信!我基本这么用了,大概齐吧。
var sw = Stopwatch.StartNew();
for (int i = 0; i < 1000; i++)
{
MyMethod();
}
sw.Stop();
Console.WriteLine($"耗时: {sw.ElapsedMilliseconds}ms");
这种做法存在以下严重问题:
- 冷启动问题 - JIT编译影响首次执行
- GC干扰 - 垃圾回收随时可能触发
- CPU调度影响 - 操作系统任务调度不可控
- 循环展开优化 - 编译器可能进行意外优化
- 数据量选择随意 - 缺乏统计学依据
🛠️ 解决方案:BenchmarkDotNet的五大核心优势